1 JavaScript 的内存机制
问题1:JavaScript 是如何存储数据的?
JavaScript 是动态语言,在声明变量之前不需要确认变量的数据类型。JavaScript 引擎在运行代码的时候自己会计算出变量的类型。
JavaScript 是弱类型语言,它支持隐式类型转换。可以使用同一个变量保存不同类型的数据。
JavaScript 有 7 种原始类型数据:
- null、undefined、number、boolean、string、symbol、bigInt
JavaScript 有 1 种引用类型数据:
- object

如上图所示,JavaScript 在执行过程中, 有三种类型内存空间:
- 代码空间:存储可执行代码。
- 栈空间:就是调用栈,存储执行上下文、原始类型数据。
- 堆空间:存储闭包、引用类型数据
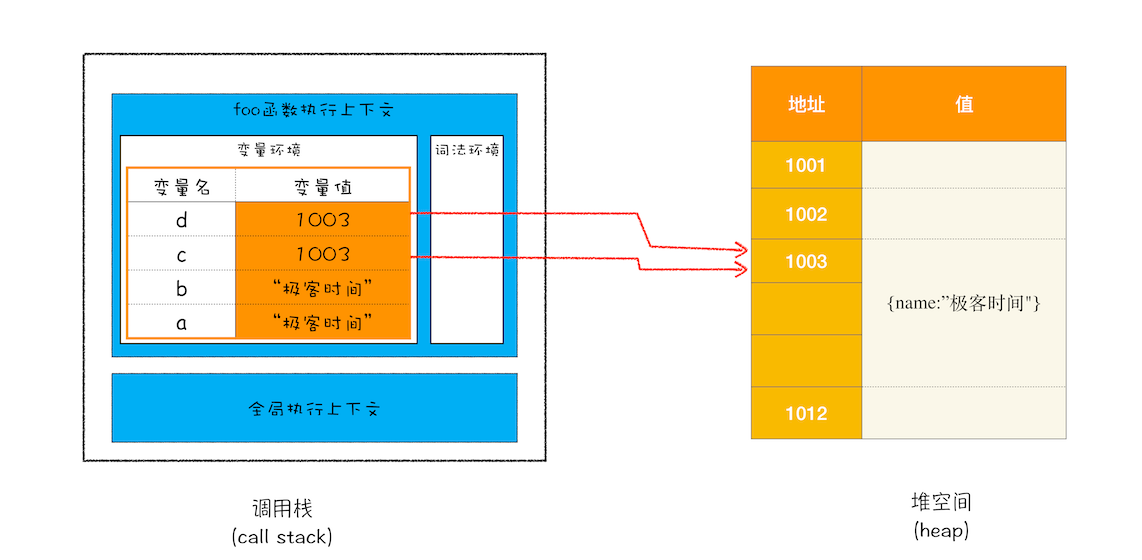
举例:
function foo(){
var a = "极客时间"
var b = a
var c = {name:"极客时间"}
var d = c
}
foo()
下图可以看到,对象类型是存放在堆空间的,在栈空间中只是保留了对象的引用地址。当 JavaScript 需要访问该数据的时候,是通过栈中的引用地址来访问的,相当于多了一道转手流程。
为什么要把引用数据类型全部存在堆内存中?
因为 JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。
所以通常情况下,栈空间的体积偏小,主要用来存放原始类型的小体积数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到空间更大的堆中。堆内存的缺点是 分配内存 和 回收内存 都会有一定的开销。
问题2:闭包的存储机制是怎样的?
闭包存储在堆空间中。
通过一段代码距离:
function foo() {
var myName = "极客时间"
let test1 = 1
const test2 = 2
var innerBar = {
setName:function(newName){
myName = newName
},
getName:function(){
console.log(test1)
return myName
}
}
return innerBar
}
var bar = foo()
bar.setName("极客邦")
bar.getName()
console.log(bar.getName())
当执行这段代码的时候,你应该有过这样的分析:
- 由于变量
myName、test1、test2都是原始类型数据,所以在执行foo函数的时候,它们会被压入到调用栈中; - 当 JavaScript 引擎执行到
foo函数时:- 首先进入编译阶段,创建一个空执行上下文,然后依次声明
myName,test1,test2,innerBar变量。 - 之后进入运行阶段,当执行到对
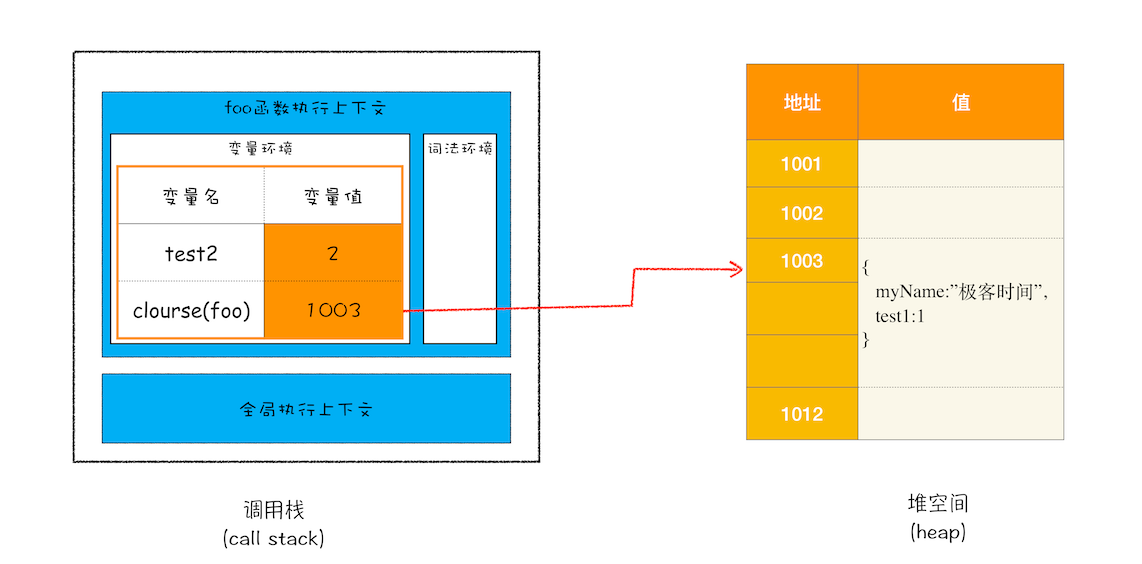
innerBar赋值的代码时,发现其内部函数setName和getName引用了外部函数foo的变量nyName和test1。- 内部函数引用外部变量,这就形成了一个 闭包。所以,此时会在堆内存中创建一个
closure(foo)对象,存储foo的变量nyName和test1。 - 然后,在
foo执行上下文中的环境变量中,删除变量nyName和test1的信息,通过引用closure(foo)对象获取myName和test1,如下图。
- 内部函数引用外部变量,这就形成了一个 闭包。所以,此时会在堆内存中创建一个
- 最后当
foo函数执行完毕,返回innerBar后,foo执行上下文销毁,test2变量也一并被销毁。- 但是在堆内存中的
closure(foo)依然保存了myName和test。 - 返回的
innerBar对象中,内部属性[[Scopes]]保存了对Closure(foo)的引用。可以顺利访问到闭包的内容。
- 但是在堆内存中的
- 首先进入编译阶段,创建一个空执行上下文,然后依次声明
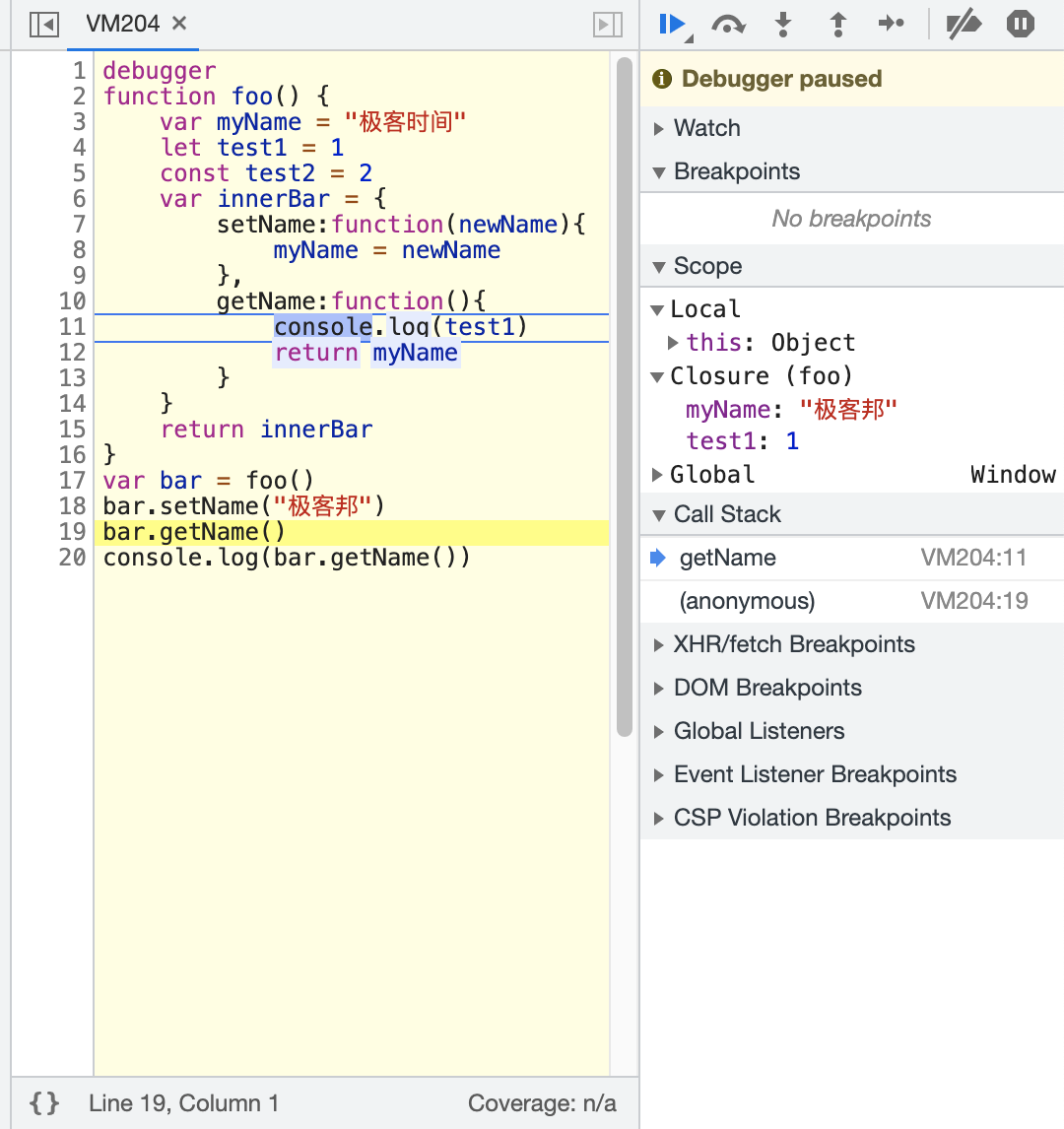
下图可以看到,getName 方法引用了 foo 闭包 CLosure(foo)。这个引用保存在内部属性 [[Scope]] 中,形成完整的作用域链。
总的来说,产生闭包的核心有两步:
第一步是需要预扫描内部函数;
第二步是把内部函数引用的外部变量保存到堆中。
问题3:垃圾数据是如何自动回收的?
C/C++ 使用手动回收策略,何时分配内存、何时销毁内存都是由代码手动控制的。
JavaScript、Java、Python 等语言,产生的垃圾数据是由垃圾回收器来释放的。
因为数据是存储在栈和堆两种内存空间中的,所以接下来我们就来分别介绍 栈中的垃圾数据 和 堆中的垃圾数据 是如何回收的。
栈中的垃圾数据:通过 ESP 指针的移动,直接抛弃。
堆中的垃圾数据:垃圾回收器 通过三个步骤:标记对象、回收内存、整理内存,完成回收工作,具体划分为:
- 新生代的回收内存,副垃圾回收器通过 Scavenge 算法,利用 对象/空闲 两个区域来回 翻转 实现垃圾回收和整理。然后通过两次存活则 对象晋升的办法来解决容积问题。
- 老生代的回收内存,负责体积大或存活时间久的对象,主垃圾回收器通过 标记 - 清除(Mark-Sweep)算法 和 标记 - 整理(Mark-Compact)算法 来回收和整理内存。
最后,
因为垃圾回收器执行时间过长(尤其是老生代的工作时间长),产生了主线程工作 全停顿(Stop-The-World)现象等待垃圾回收的问题。
对此,解决方案是利用 增量标记(Incremental Marking)算法 ,把垃圾标记的任务拆分成多个小任务,在 JavaScript 代码执行中穿插完成,减小卡顿问题。
1 调用栈中的数据回收
当一个函数执行结束之后,JavaScript 引擎会通过向下移动 ESP 来销毁该函数保存在栈中的执行上下文。
通过一段代码理解:
function foo(){
var a = 1
var b = {name:"极客邦"}
function showName(){
var c = 2
var d = {name:"极客时间"}
}
showName()
}
foo()
当执行到第 6 行代码时,其调用栈和堆空间状态图如下所示:
在调用栈中,还有 一个记录当前执行状态的指针(称为 ESP),指向调用栈中 showName 函数的执行上下文,表示当前正在执行 showName 函数。
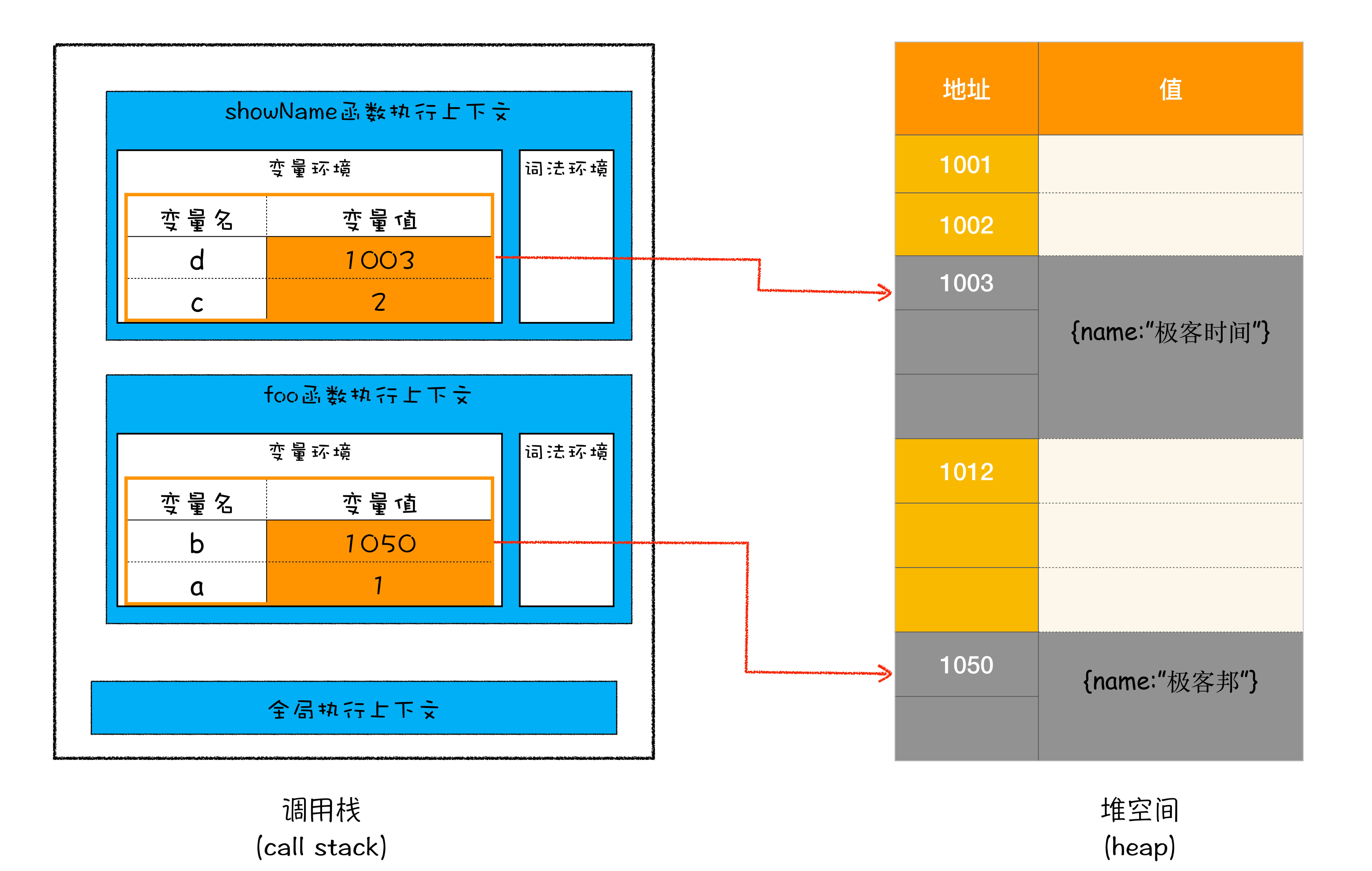
当 showName 函数执行完成之后,函数执行流程就进入了 foo 函数,那这时就需要销毁 showName 函数的执行上下文了。ESP 这时候就帮上忙了,JavaScript 会将 ESP 下移到 foo 函数的执行上下文,这个下移操作就是销毁 showName 函数执行上下文的过程。
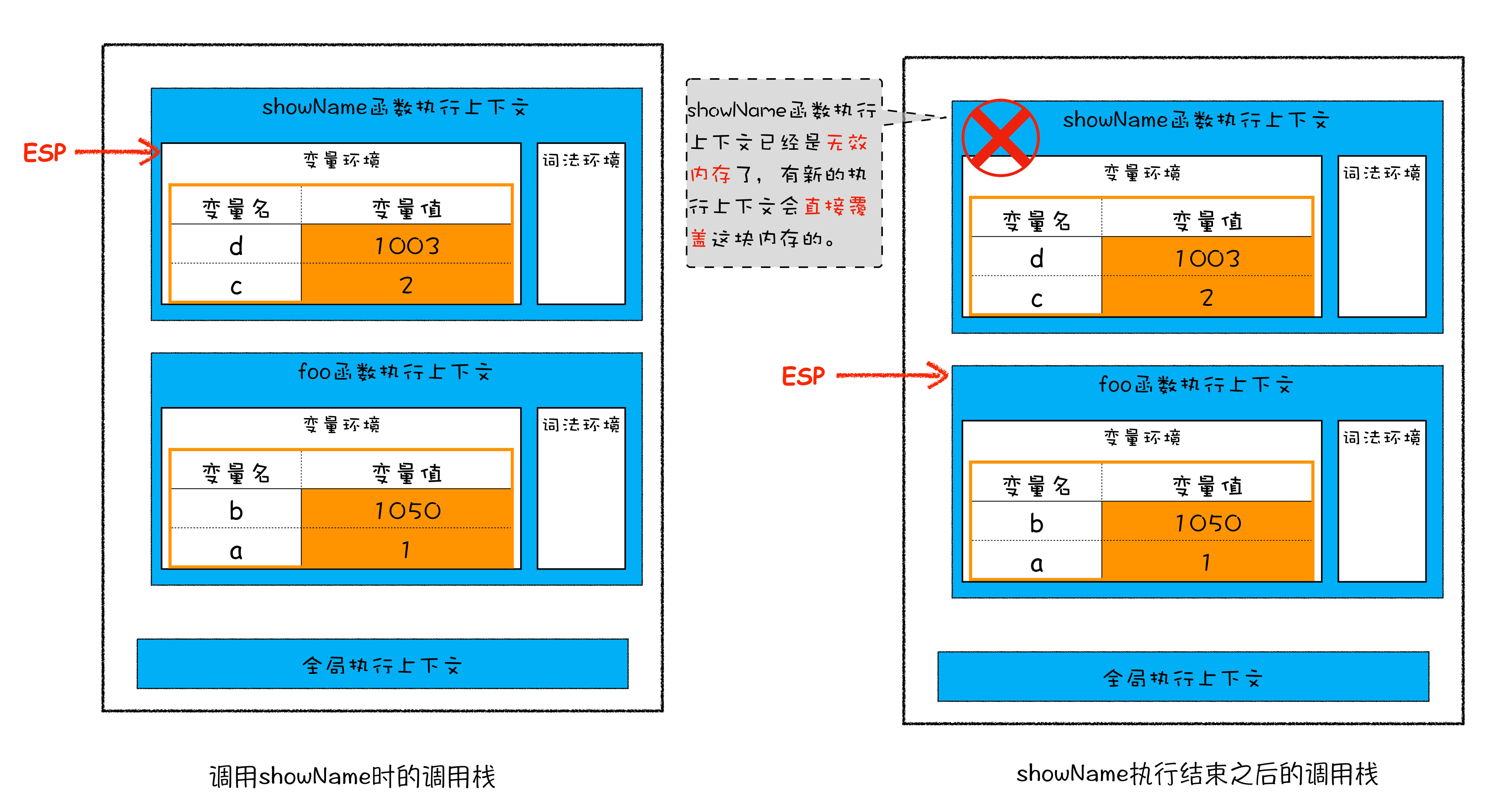
从图中可以看出,当 showName 函数执行结束之后,ESP 向下指向 foo 函数的执行上下文。上面 showName 的执行上下文虽然保存在栈内存中,但是已经是无效内存了。当有新的执行上下文加入时,这块内容会就会被直接覆盖掉。
所以说,当一个函数执行结束之后,JavaScript 引擎会通过向下移动 ESP 来销毁该函数保存在栈中的执行上下文。
2 堆中的数据回收
要回收堆中的垃圾数据,就需要用到 JavaScript 中的 垃圾回收器 了。
2.1 代际假说
代际假说(The Generational Hypothesis)是一个垃圾回收的基础理论:
大部分对象在内存中存在的时间很短。简单来说,就是很多对象一经分配内存,很快就变得不可访问(不再使用,没有指针指向这些对象);
不死的对象,会活得更久。
2.2 分代收集
分代收集是 V8 引擎采用的垃圾回收策略。
在 V8 中会把堆分为 新生代 和 老生代 两个区域。
- 新生代:存放生存 时间短的对象,新生区通常只支持 1~8M 的容量。副垃圾回收器,主要负责新生代的垃圾回收。
- 老生代:存放生存 时间久的对象。老生区支持非常大的容量。主垃圾回收器,主要负责老生代的垃圾回收。
2.3 垃圾回收器的工作流程
不论什么类型(主/副)的垃圾回收器,它们都有一套共同的执行流程。
第一步:标记对象。标记空间中 活动对象(还在使用的对象) 和 非活动对象(可以进行垃圾回收的对象)。
第二步:回收内存。回收非活动对象所占据的 内存,统一清理内存中所有被标记为可回收的对象。
第三步:整理内存。频繁回收对象后,内存中就会存在大量不连续空间,称为内存碎片。需要移动内存碎片,空出连续的空间,
- 当内存中出现了大量的内存碎片,如果需要分配较大连续内存的时候,就有可能出现内存不足的情况。
副垃圾回收器
副垃圾回收器主要负责新生区的垃圾回收。而通常情况下,大多数小的对象都会被分配到新生区,所以说这个区域虽然不大,但是垃圾回收还是比较频繁的。
新生代中用 Scavenge 算法 来处理。
所谓 Scavenge 算法,是把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域,如下图所示:
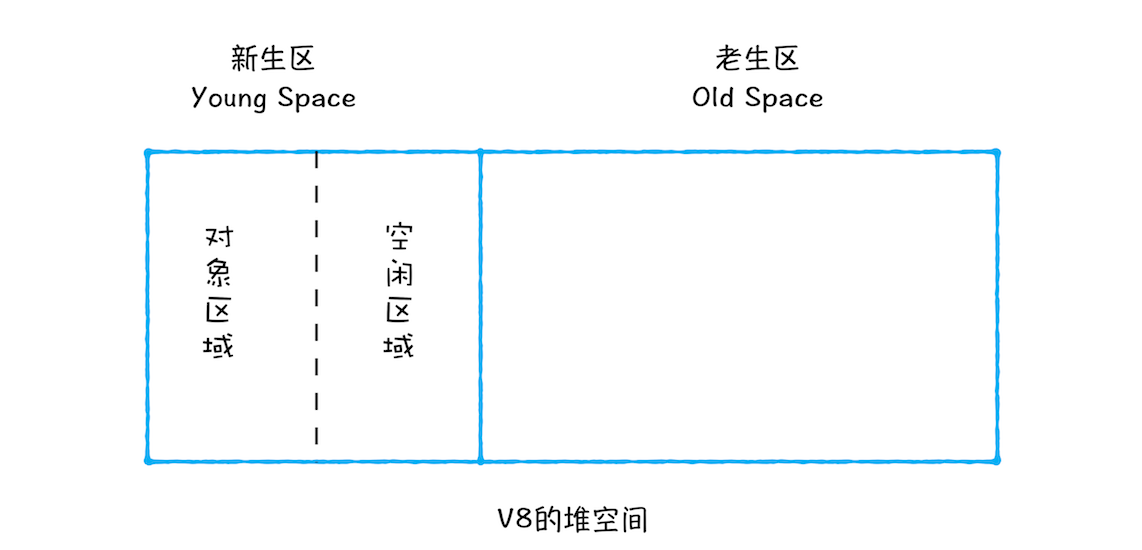
流程如下:
新加入的体积较小的对象都会存放到对象区域。当对象区域快被写满时,就需要执行一次垃圾清理操作。
标记对象。标记空间中活动对象和非活动的垃圾对象。
回收内存 + 整理内存。把存活的活动对象复制到空闲区域中,在复制的过程中,同时把这些对象进行有序排列。所以回收内存的同时也完成了碎片的整理。
角色反转。原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域。
对象晋升。经过 两次 垃圾回收依然还存活的对象,会被移动到老生区中。
探讨:
- 体积小。复制操作需要时间成本,如果新生区空间设置得太大,会导致每次清理的时间就会过久。为了 执行效率,一般新生区的空间会被设置得比较小。
- 新生区的空间不大,所以很容易被存活的对象装满整个区域。为了解决这个问题,JavaScript 引擎采用了对象晋升策略策略。
主垃圾回收器
主垃圾回收器主要负责老生区中的垃圾回收。
老生区中对象的来源:
- 一些大的对象会直接被分配到老生区。
- 从新生区晋升而来的对象。
因此老生区中的对象有两个特点:占用空间大、存活时间长。
新生代中用 标记 - 清除(Mark-Sweep)和 标记 - 整理(Mark-Compact)来处理。流程如下:
- 标记对象。挨个遍历调用栈中的全部变量,以每一个变量为根元素,遍历这组根元素。所有遍历过程中,能到达的元素称为 活动对象,没有到达的元素判断为 垃圾数据。如下图
- 回收内存:标记 - 清除(Mark-Sweep)。直接清理掉标记为垃圾数据的对象。如下图
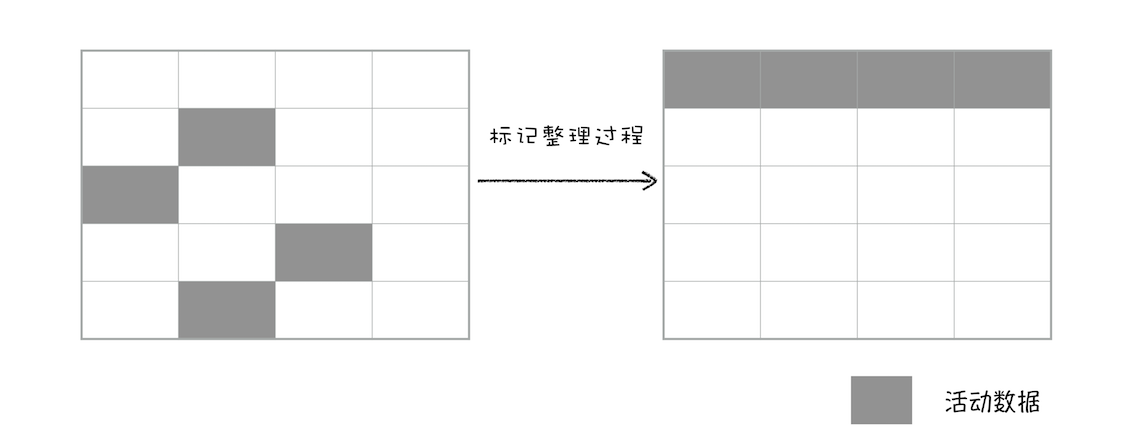
- 整理内存:标记 - 整理(Mark-Compact)。并不是每次都执行整理工作。执行时,让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。如下图
- 标记对象:
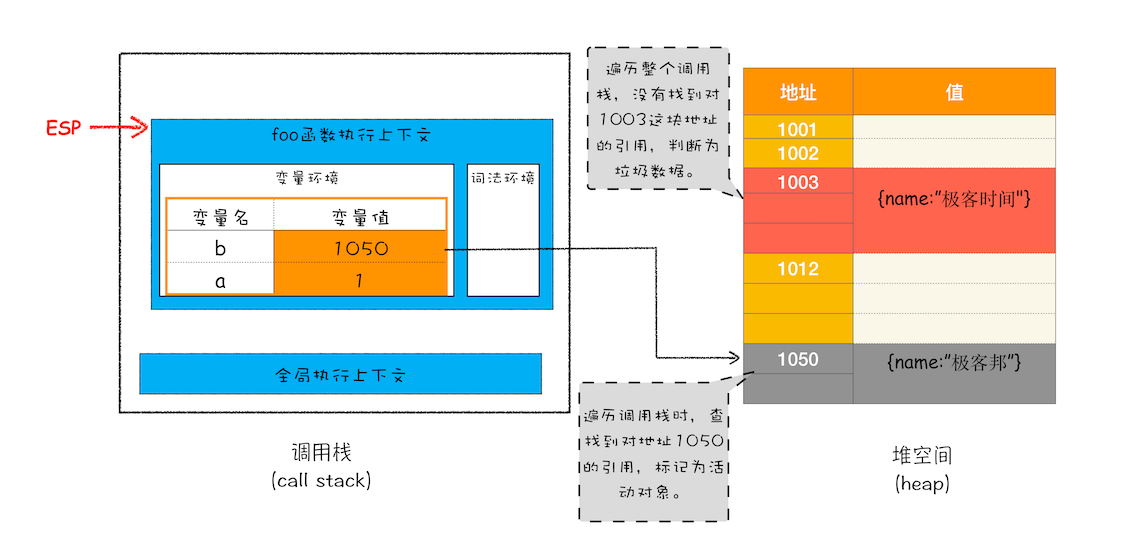
- 回收内存:标记 - 清除(Mark-Sweep)
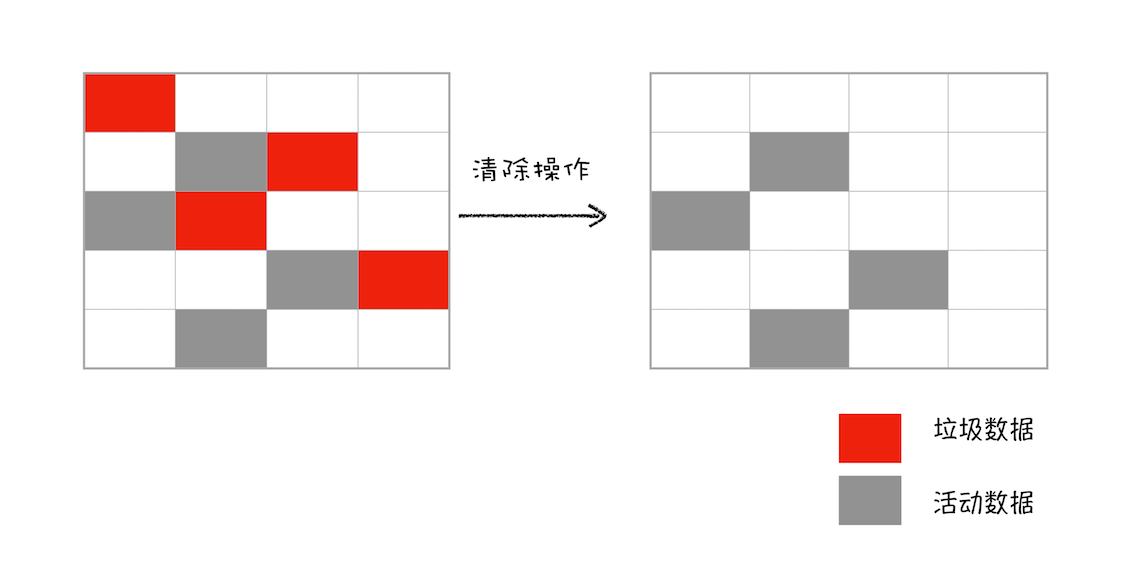
- 内存整理:标记 - 整理(Mark-Compact)
2.4 全停顿(Stop-The-World)和 增量标记(Incremental Marking)
全停顿(Stop-The-World):
由于 JavaScript 是运行在主线程之上的,一旦执行垃圾回收算法,都需要将正在执行的 JavaScript 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行。我们把这种行为叫做全停顿(Stop-The-World)。
比如堆中的数据有 1.5GB,V8 实现一次完整的垃圾回收需要 1 秒以上的时间,这也是由于垃圾回收而引起 JavaScript 线程暂停执行的时间,若是这样的时间花销,那么应用的性能和响应能力都会直线下降。主垃圾回收器执行一次完整的垃圾回收流程如下图所示:
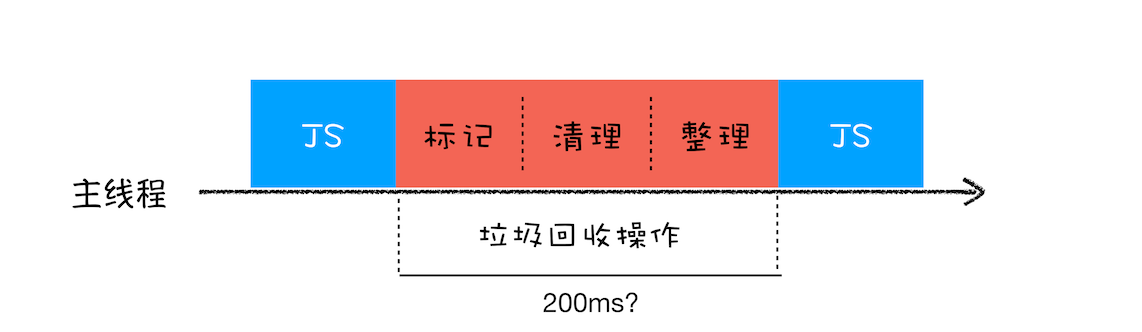
在这 200 毫秒内,主线程是不能做其他事情的。比如页面正在执行一个 JavaScript 动画,因为垃圾回收器在工作,就会导致这个动画在这 200 毫秒内无法执行的,这将会造成页面的卡顿现象。
增量标记(Incremental Marking):
这其中,对象标记需要便利整个调用栈和堆内存中的所有对象,非常耗时。
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称为 增量标记(Incremental Marking)算法。如下图所示:
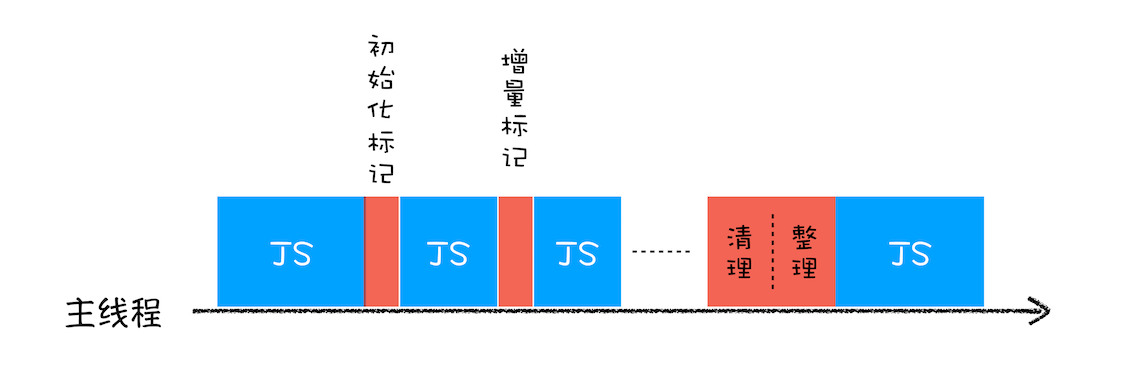
使用增量标记算法,可以把一个完整的垃圾回收任务拆分为很多小的任务。这些小的任务执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,这样当执行上述动画效果时,就不会让用户因为垃圾回收任务而感受到页面的卡顿了。
问题4:什么是内存泄露?
如果有大量的变量在业务上已没有实际意义,但却因被引用而无法正确被 GC 回收,最终导致占用内存,这个现象就叫内存泄露。
内存泄露的情况:
- 全局变量。全局变量会一直被引用,无法被 GC 回收。
- 闭包。闭包如果被引用,就无法被 GC 回收。
- 被遗忘的定时器。
setInterval会周期性的调用回掉函数,有时会忘记对setInterval进行删除。 - DOM 引用。考虑到性能或代码简洁方面,我们代码中进行 DOM 时会使用变量缓存 DOM 节点的引用,但移除节点的时候,我们应该同步释放缓存的引用,否则游离的子树无法释放。