3. 作用域链和闭包
1 基础
1. 内存管理
1.1 生命周期
- 申请:程序申请内存,系统分配你需要的内存;
- 使用:程序使用分配好的内存,如存放对象;
- 释放:当程序使用完毕后,系统释放内存资源。
- 手动管理内存:如 C、C++,包括早期的 OC,需要手动来管理内存的申请和释放(malloc 和 free 函数);
- 自动管理内存:比如 Java、JavaScript、Python、Swift、Dart 等,它们有自动帮助我们管理内存;
1.2 Js 的内存管理
- 基本数据类型:内存的分配会在执行时, 直接在 调用栈 进行分配;
- 复杂数据类型:内存的分配会在 堆内存 中开辟一块空间,然后在调用栈中,有一个指针指向堆内存的变量。
闭包也保存在堆内存中。
1.3 垃圾回收
垃圾回收分为:栈的垃圾回收,堆的垃圾回收。
- 栈的垃圾回收依赖于调用栈的出栈;
- 堆的垃圾回收依赖于 GC 机制。
Garbage Collection,GC。是现代编程语言的垃圾回收机制。
常见有三种 GC 算法(浏览器相关文章 存储机制 中有介绍):
- 引用计数
- 当一个对象有一个引用指向它时,那么这个对象的引用就 +1,当一个对象的引用为 0 时,这个对象就可以被销毁掉;
- 这个算法有一个很大的弊端就是会产生循环引用;
- 标记清除
- 这个算法是设置一个根对象(root object),垃圾回收器会定期从这个根开始,找所有从根开始有引用到的对象,对于哪些没有引用到的对象,就认为是不可用的对象;
- 这个算法可以很好的解决循环引用的问题,Js 使用的是该方法。
1.4 Js 中垃圾回收
更详细内容,见:浏览器-存储机制
基本原理:
- 代际假说:大部分对象在内存中存在的时间很短。不死的对象,会活得更久。
- 分代收集:在 V8 中会�把堆分为 新生代(副垃圾回收器) 和 老生代(主垃圾回收器) 两个区域。
工作流程:
-
主回收器工作流程 (3):标记对象、回收内存、整理内存。
-
副回收器的工作流程(4):标记对象、回收内存、整理内存、角色反转、对象晋升。
-
Scavenge 算法:新生代把空间对半划分:对象区域 + 空闲区域。
-
标记对象。标记空间中活动对象和非活动的垃圾对象。
-
回收内存 + 整理内存。把存活的活动对象复制到空闲区域中,在复制的过程中,同时把这些对象进行有序排列。所以回收内存的同时也完成了碎片的整理。
-
角色反转。原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域。
-
对象晋升。经过 两次 垃圾回收依然还存活的对象,会被移动到老生区中。
-
-
对象晋升:
新生代中用 **标记 - 清除(Mark-Sweep)**和 **标记 - 整理(Mark-Compact)**来处理。流程如下:
- 标记对象。挨个遍历调用栈中的全部变量,以每一个变量为根元素,遍历这组根元素。所有遍历过程中,能到达的元素称为 活动对象,没有到达的元素判断为 垃圾数据。
- 回收内存:标记 - 清除(Mark-Sweep)。直接清理掉标记为垃圾数据的对象。
- 整理内存:标记 - 整理(Mark-Compact)。并不是每次都执行整理工作。执行时,让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
优化:
增量标记(Incremental Marking),解决全停顿(Stop-The-World)现象。
- 全停顿:这是因为 Js 运行在浏览器的主线程之上,而一旦执行垃圾回收算法,就会阻塞接下来的 js 脚本执行,造成卡顿。
- 增量标记:V8 把标记过程划分为多个子过程,让 GC 回收不会一次性完成,而是分多次和 Js 脚本交替进行,减小 Js 阻塞,减小页面动画等卡顿(16sm 一帧,这里涉及到浏览器的调度机制)。
2. 作用域链
首先,通过一段代码理解作用域链:
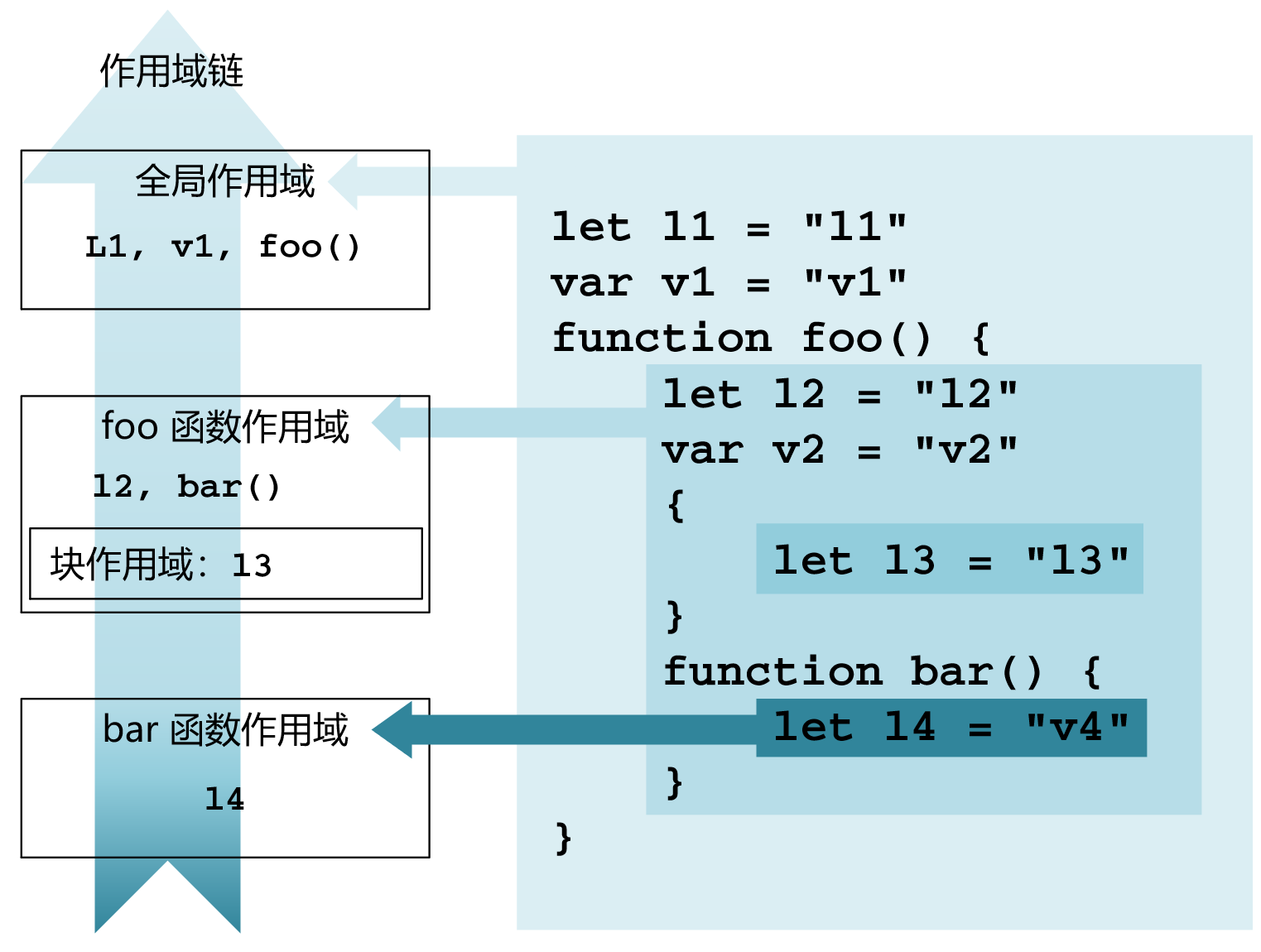
当一个代码块嵌套在另一个代码块中时,就发生了作用域的嵌套;作用域之前发生嵌套关系,就形成了作用域链。
作用域链是 静态 的,它只受变量和函数的声明位置决定。不同作用域的嵌套关系在分析代码时可以得出,在 编译前 引擎便能确定,和 执行上下文无关 。
执行上下文/作用域链
当引擎在逐行执行代码时,如果遇到一个函数调用,引擎就会对应的创建一个执行上下文。每个执行上下文中都有一个 outer(在变量环境中)。这个 outer 指向该函数定义的时候所在作用域,有时它是一个执行上下文,有时它是一个闭包。
- 更多关于闭包的知识,参考 "�闭包 Closure" 章节。闭包是一系列变量的集合,是一个执行上下文的缩减版。
所以,outer 就是外层作用域,outer 永远指向外层作用域对应的执行上下文(或闭包)。外层作用域是在定义的时候就已经确定了的,和如何调用,在哪里调用无关。
作用域链:不同的执行上下文(闭包)通过 outer 得以形成关系,这种串联的关系就是作用域链。
这是一个代码片段在执行中的暂停:
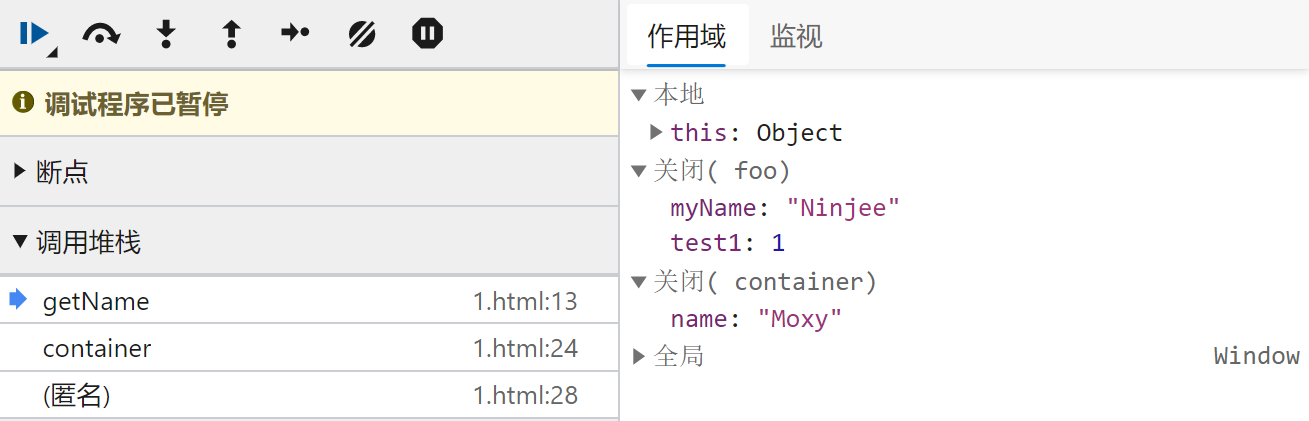
可以从开发者工具中看到,在getName 执行上下文中,作用域(scope)保存了:
this值:指向一个 Object 通常是它的调用者。foo闭包(closure):当前执行上下文(getName)的outer属性指向foo闭包。container闭包(closure):foo闭包的outer属性指向container闭包。- Global:
container闭包的outer属性指向了全局执行上下文,也就是 Global。
2.3 作用域链的查找
通过上文的代码举例:
当引擎处在 bar 作用域中时,假设它想访问变量 v1。
- 引擎会先在当前作用域中(
bar作用域)查找同名变量; - 若没有找到,就会通过执行上下文的
outer属性访问外层作用域(foo作用域),查找同名变量; - 若没有依然没有找到,就再通过
foo执行上下文中的outer属性去访问更外层的作用域(全局作用域)。最终,引擎找到了v1变量。
引擎会沿着作用域链,依次查找每一个执行上下文中的变量名,一旦找到同名变量,则返回这个变量。若没有找到,则会一直向上查找,直到全局作用域为止。
这就是说,一条作用域链好比一幢建筑物。最顶层表示全局作用域,逐层嵌套的作用域表示逐层向下递减的楼层,最底层就是嵌套最深的作用域。这是一个从下向上的访问链,下层可以访问上层中的变量,而上层无法访问下层中的变量,如上图的向上箭头所示。
LHS / RHS
影响作用域链查找的还有 LHS 和 RHS。
LHS(left-hand Side)引用:查找并引用变量的 名称(key),通常在赋值运算符的左边。
RHS(right-hand Side)引用:查找并引用变量的 值(value),通常在赋值运算符的右边。
举例来说:
// 以下a变量都是 LHS
a = 3;
a = b;
// 以下a变量都是 RHS
myName = a;
console.log(a);
a(2); // a是函数;
在变量还没有被声明(在任何作用域中都无法找到变量)的情况下,这两种查询的行为是不一样的。
情况 1:如果变量没有声明,进行 RHS 操作:
function foo(a) {
console.log(a + b); // ReferenceError: b is not defined
b = a;
}
foo(2);
上段代码中,第二行 console.log( a + b ) 中的 b 变量没有进行声明。所以当执行到这里时,引擎进行 RHS 查询 b 变量的值。最终会抛错: ReferenceError: b is not defined。
情况 2:如果变量没有声明,进行 LHS 操作:
function foo(a) {
b = a;
console.log(a + b); // 4
}
foo(2);
上段代码中,b 变量没有任何声明,当执行到 b = a 时,引擎为了获取 b 变量的变量名而进行作查询。沿着当前 foo 作用域,找到全局作用域,都没有找到该变量。之后,引擎不会报错,而是会在全局作用域中通过 var 声明 创建一个同名变量,并返回这个变量。
- 严格模式下,会报错:
"use strict";
function foo(a) {
b = a;
console.log(a + b); // ReferenceError: b is not defined
}
foo(2);
所以,我们要避免未声明变量,就直接在代码调用变量。轻则报错(RHS),重则造成内存浪费(LHS)。
3. 闭包 Closure
通常来讲,对闭包有以下三种理解:
概念一(浏览器工作原理与实战):闭包是内部函数引用外部函数的变量的集合。
概念二(Js 高程):闭包是指有权访问另一个函数作用域中的变量的函数。
概念三(MDN):闭包是函数和声明该函数的词法环境的组合,是一个函数和对其周围状态(lexical environment, 词法环境)的引用捆绑在一起。
3.1 变量的集合
本文采用概念一对闭包的定义,闭包是一系列变量的集合。
在 JavaScript 中,根据词法作用域中作用域嵌套的规则,如果外部函数内嵌套了一个内部函数,那么内部函数总是可以访问外部函数中声明的变量。
当通过调用一个外部函数返回一个内部函数后,即使这个外部函数已经执行结束了,但是若内部函数引用了外部函数的变量,那么这些被引用的变量会依然保存在内存中,我们就把这些变量的集合称为闭包。
比如外部函数是 foo,那么这些变量的集合就称为 foo 函数的闭包。
举例来说,
function foo() {
var name = "Moxy";
var age = 18;
function callName() {
console.log(name);
}
return callName;
}
var call = foo();
call(); // Moxy
这段代码中,全局作用域是无法访问 foo 函数内部的 name 变量的。但是通过调用外部函数 foo,返回了一个名为 callName 的内部函数,该内部函数引用了 name 变量。所以,全局作用域通过这个内部函数 callName 拥有了对 name 的访问权。这就形成了一个 foo 闭包。
3.2 执行上下文的精简
闭包是对一个执行上下文的精简。在即将销毁一个执行上下文时,如果该执行上下文内部有被其他作用域引用的变量,则会把这些变量进行打包,只销毁用不到的用不到变量和其他结构,就这样形成了一个闭包 Closure。
换句话说,闭包没有包含整个变量环境和词法环境,只包含用到的变量。这是因为在返回内部函数时,JS 引擎会提前分析闭包内部函数的相关内容,有被子作用域引用的变量,不会被 gc 回收;而没有被引用到的,全部被 gc 回收。
从上一小节的例子中我们知道:即使 foo 被执行完毕,也不会立刻从内存中销毁。这是因为全局作用域�通过 call 变量,依然持有对 callName 函数和 name 变量的访问权。
事实上在 foo 执行完毕后, foo 的执行上下文没有全部删除,而是删掉了绝大多数不需要的内容: this, outer 等等。对于登记在 foo 执行上下文内的所有变量和函数,也只保留了被其他作用域所持有的变量,其他的变量和函数则全部被销毁了。
如下图,在上一小节的案例中,foo 的执行作用域在被销毁前,转化为了一个 foo 闭包。
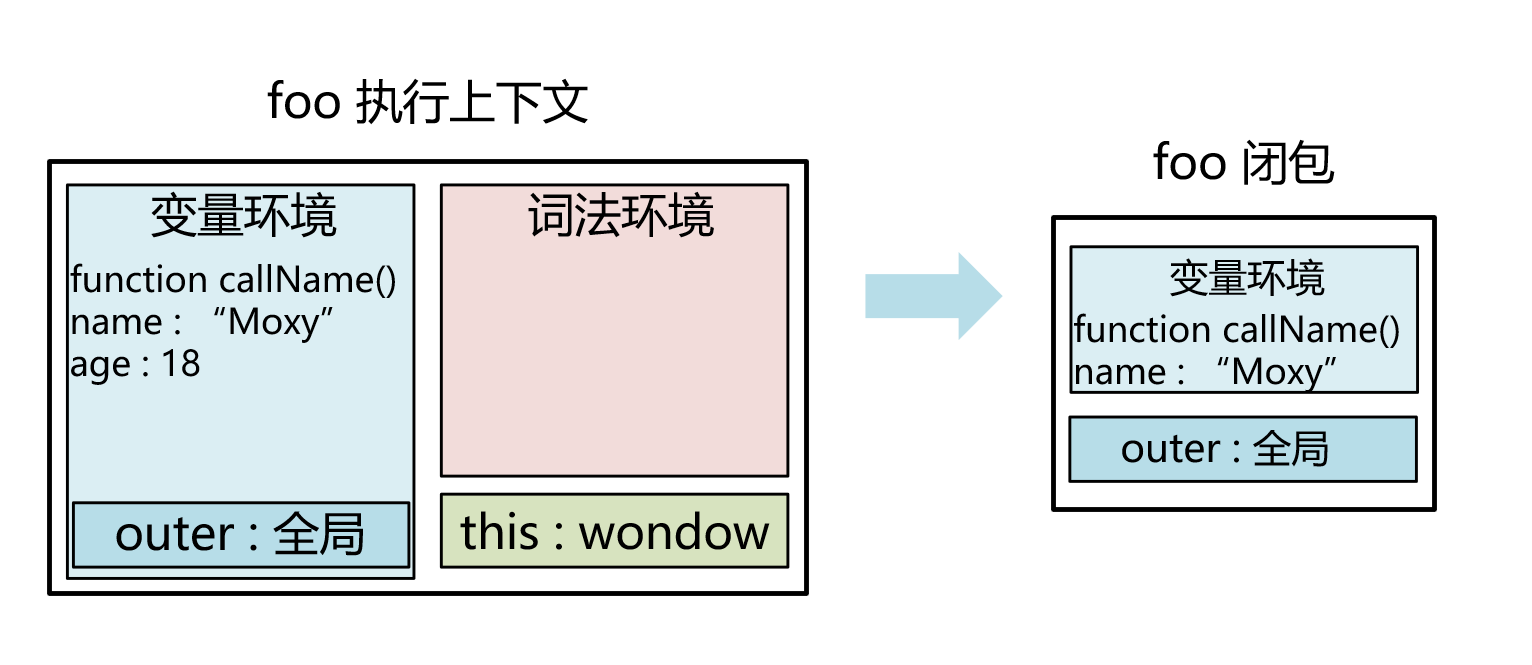
foo 中 age 变量并没有被引用,引擎会对 foo 闭包进行优化,只保留被引用的 name 和 callName,age 变量随着 foo 执行完毕被销毁了。
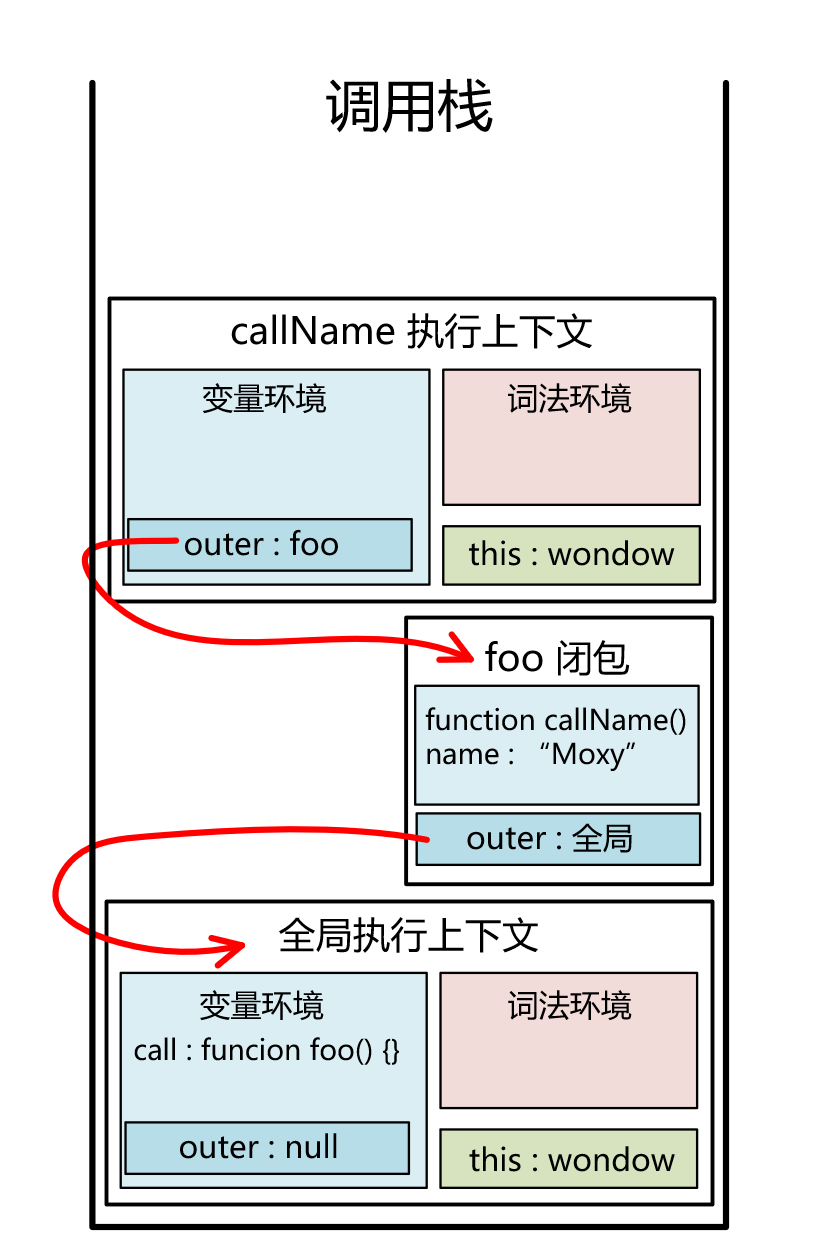
随后, foo 闭包被绑定在 callName 执行上下文中的内置特性 [[scope]] 作用域链上。
当在全局执行环境中调用 call() (第 11 行代码) 时, callName 执行上下文入栈。由下图,可以在开发者工具中看到,callName 执行上下文的 scope 内,存在一个名为 foo 的闭包(closure)。
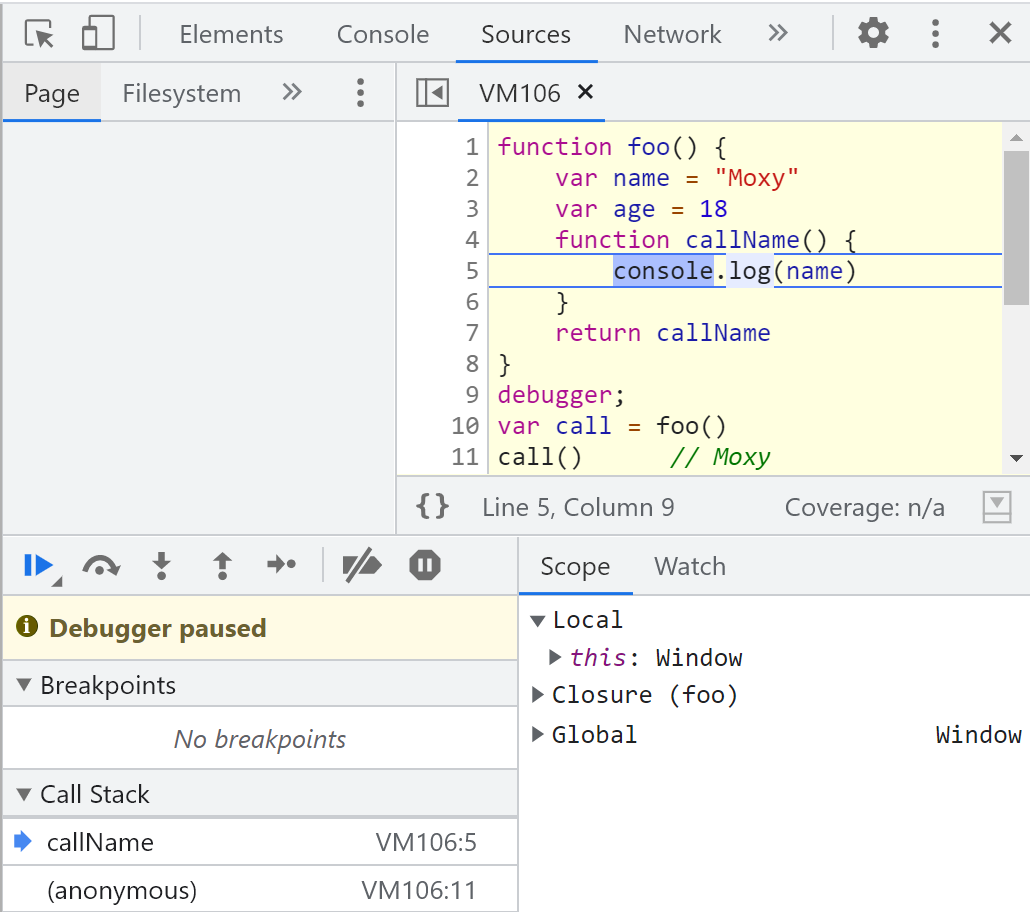
3.3 作用域链中的一环
从上一小节的例子中我们可以得出一个结论:闭包是作用域链中的一环。
到此,我们可以得出一个完整的作用域链:
查找一个变量,做作用域链的顺序是这样的:
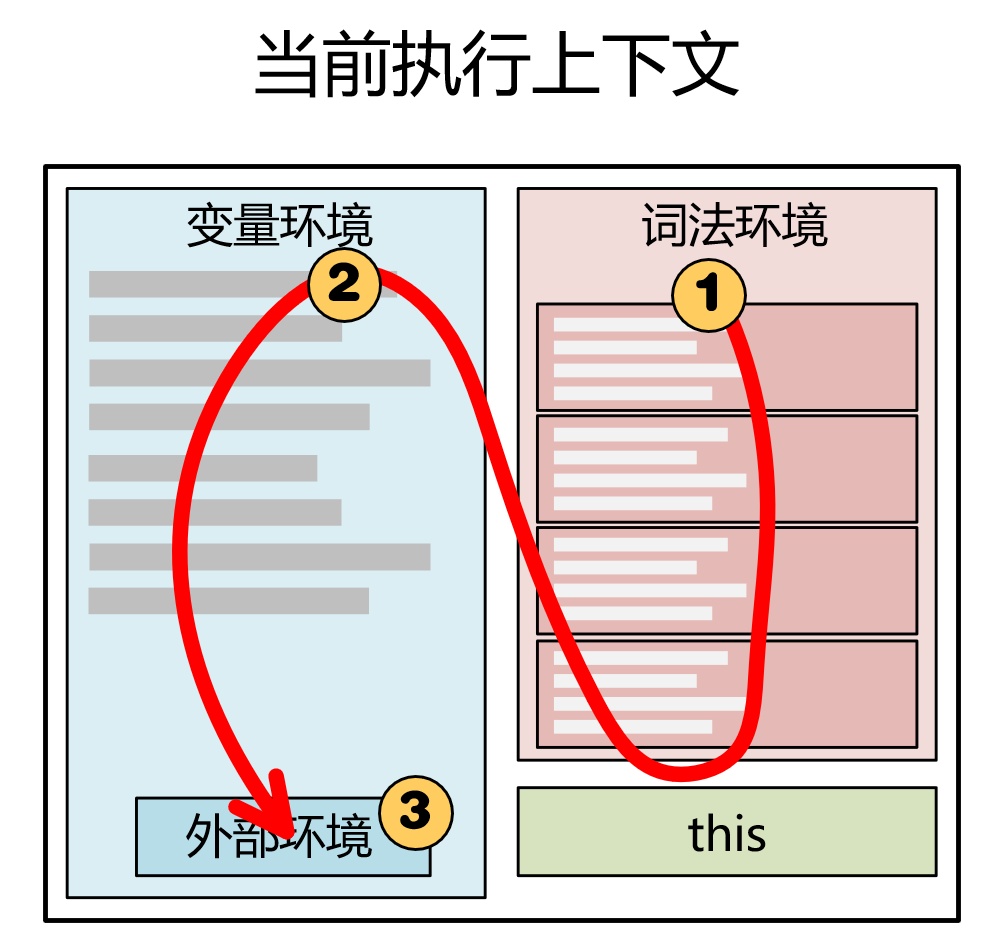
- 先从执行上下文的内部开始查找:词法环境栈由上至下 ------> 环境变量内登记的变量 ------>
outer外部环境 - 如果在当前执行上下文内部找不到所要的变量,就会通过
outer去它的外层作用域查找。- 在外层作用域中,依然会有这一套顺序:词法环境栈由上至下 ------> 环境变量内登记的变量 ------>
outer外部环境
- 在外层作用域中,依然会有这一套顺序:词法环境栈由上至下 ------> 环境变量内登记的变量 ------>
- ....
- 查找会顺着
outer一直到最外层的全局执行上下文中查找。
在一个执行上下文内部的作用域链:
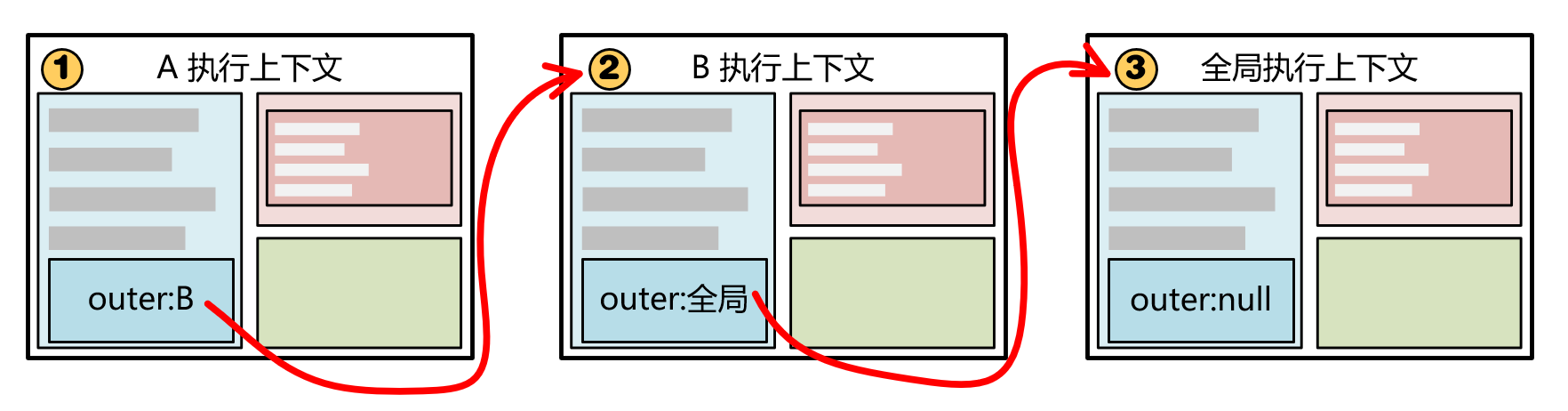
在多个执行上下文之间的作用域链:
- 需要注意的是,多个执行上下文之间的作用域链是通过
outer属性链接的。作用域链由函数声明时的位置决定,和调用顺序无关,自然和执行上下文栈的结构无关。
3.4 堆内存中的闭包
闭包是保存在堆内存中的。
如果有堆和栈的知识可以知道,函数的执行上下文是保存在调用栈中的,而调用栈会保存在栈内存中,方便快速读取其中的数据。函数的执行上下文自然也保存在栈内存中。
闭包的形成:
当一个函数中有几个变量形成一个闭包后,这个闭包就会从这个函数执行上下文中拿出来,然后保存在堆内存中。同时会删除这几个变量在这个函数执行上下文中的引用信息。最后,这个函数执行上下文中会保留一份对闭包的引用,这样一个闭包就形成了。
3.5 闭包的缺点
内存泄漏。
通俗说,必包延长了变量的生命周期,使这些原本应当销毁的变量继续留存在内存中。当这些变量不再需要时,如果依然保持引用,则变量依然没有销毁,变量多余的生命周期就是内存泄漏。
- 解决:当闭包不再使用时,保持的引用赋值为
null等其他值,只要解除对闭包的引用,即可放它入土。
对于一个闭包来说,只要有一个函数执行上下文拥有对它的引用。这个闭包就无法被 GC 回收。
如果大量使用闭包,且有常驻调用栈的函数大量引用了闭包,这导致大量闭包长期保存在堆内存中,消耗大量内存。最终影响网页的性能。
所以,闭包的使用有可能会占用大量内存、进而造成内存泄漏。
总结一
通过下面的这一段代码,来理解 作用域链 和 执行上下文 之间的关系:
function bar() {
var animal = "cat";
let age = 1;
if (1) {
let animal = "dog";
console.log(myAge);
}
}
function foo() {
var animal = "pig";
let age = 2;
{
let age = 3;
bar();
}
}
var animal = "monkey";
let myAge = 18;
let age = 1;
foo();
当执行到 bar 函数内部的 if 语句块时,开发者工具的情况如下图所示:
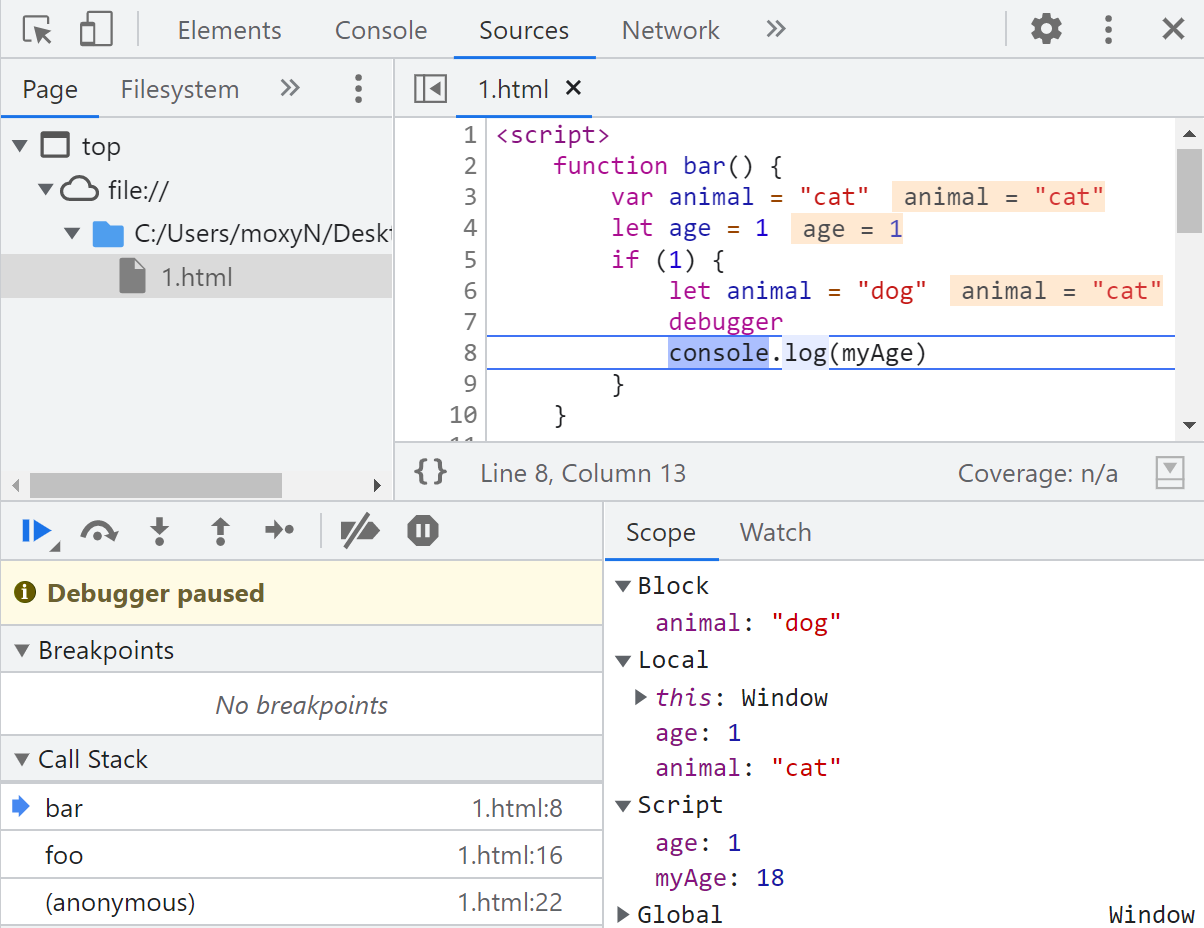
可以看到,此时的调用栈:全局执行上下文 ==> foo 执行上下文 ==> bar 执行上下文
作用域:bar 执行上下文(词法环境 ==> 变量环境) ==> 全局执行上下文(词法环境 ==> 变量环境)
此时的调用栈情况如下图:
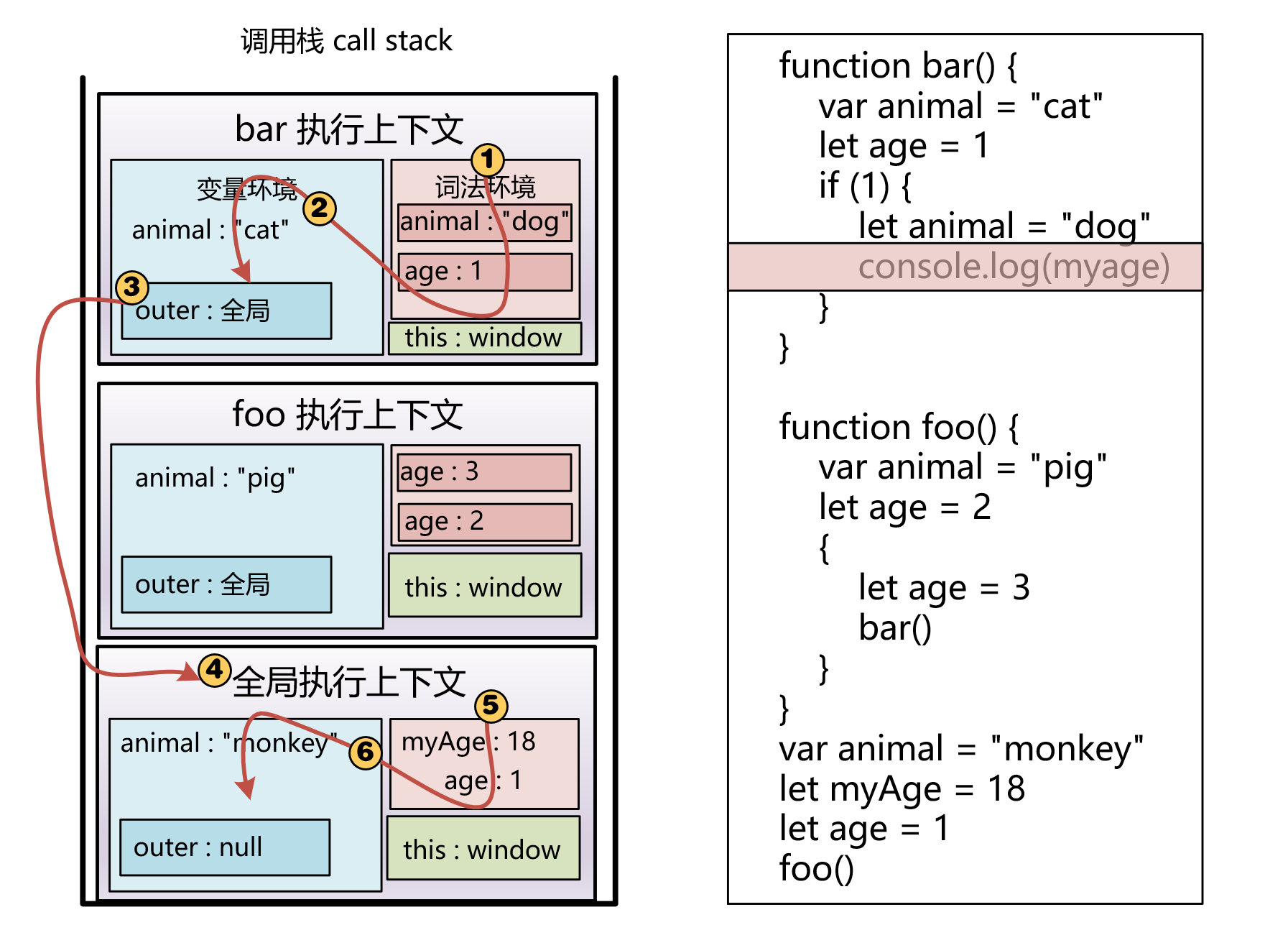
总结二
下面可以通过这一段代码,完整的思考一下 调用栈、执行上下文、outer 和 闭包 的关系。
function container() {
var name = "Moxy";
function foo() {
var myName = "Monkey";
let testLet = 1;
const testConst = 2;
var baz = {
getName: function () {
console.log(testLet);
console.log(name);
debugger; // 查看这里的调用栈状态、执行上下文和闭包
return myName;
},
setName: function (newName) {
myName = newName;
},
};
return baz;
}
var bar = foo();
bar.setName("Ninjee");
console.log(bar.getName());
}
container();
这里只分析当代码运行到 debugger 时, 调用栈、执行上下文、outer 和 闭包 的状态:
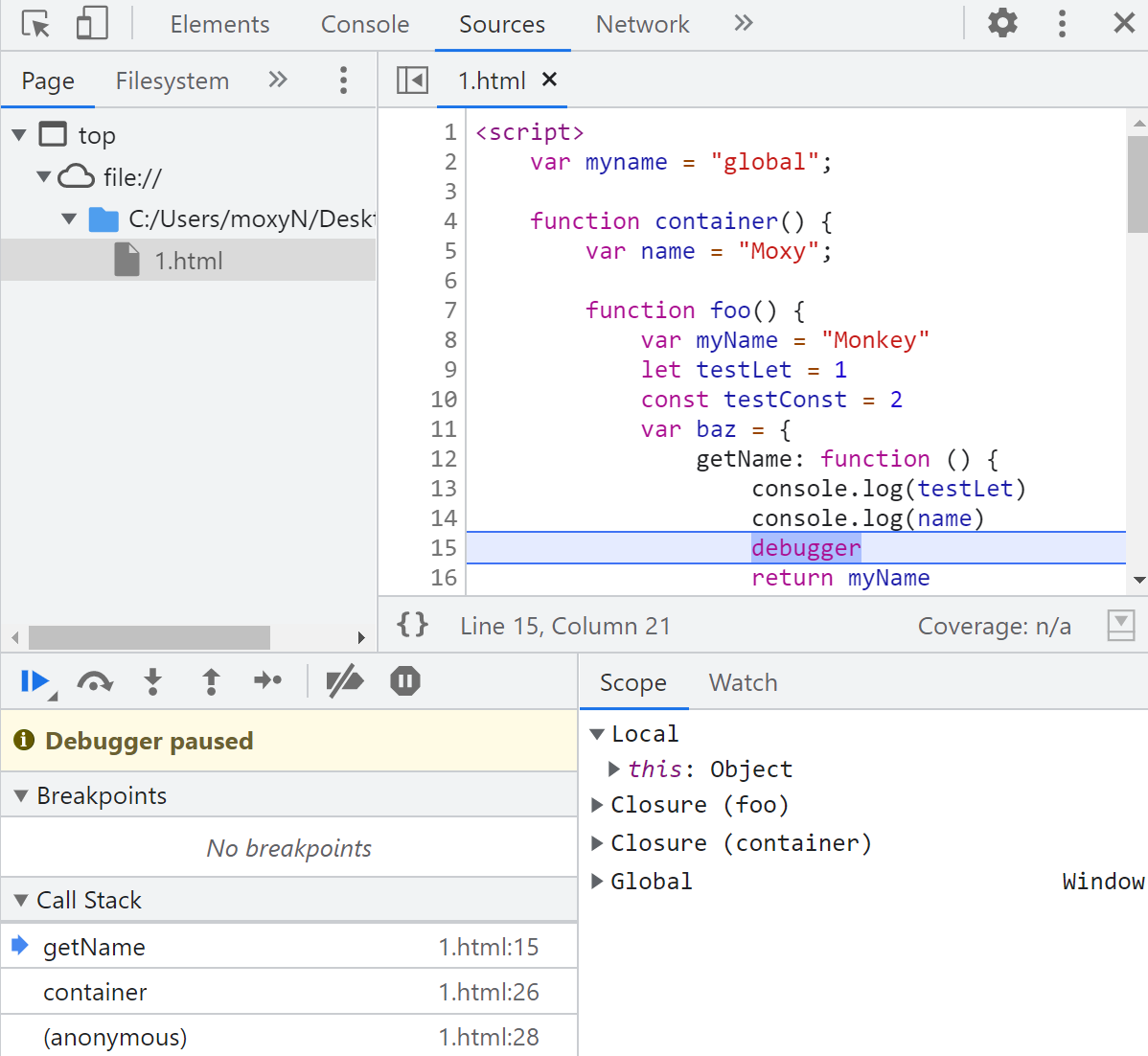
此时的调用栈:
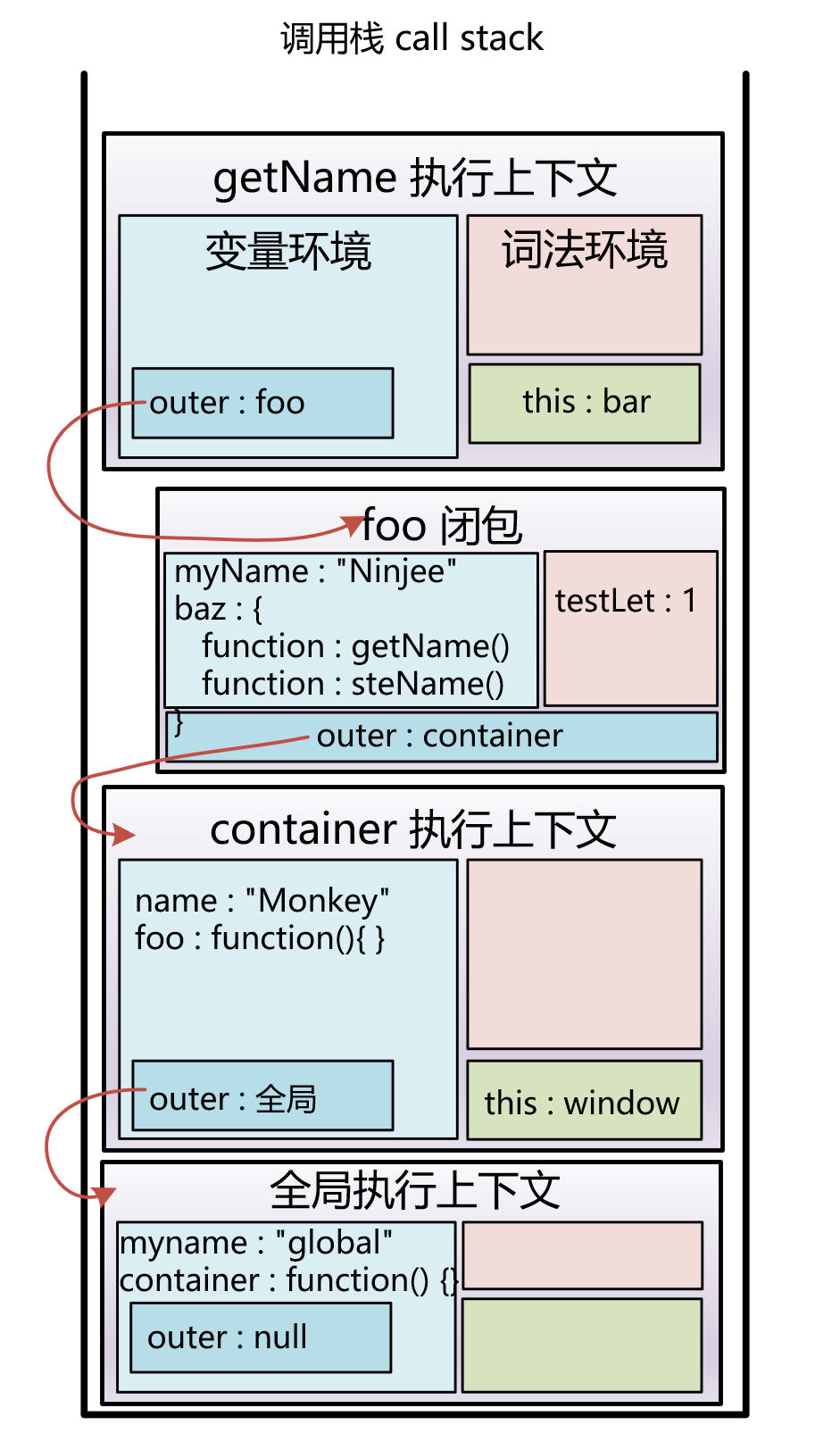
引用
《你不知道的 JavaScript》
winter - 重学前端
李兵 - 浏览器工作原理与实战