操作系统
第一章:绪论
问题:什么是操作系统
计算机的硬件、软件有一种层次关系。硬件在最底层,上层是操作系统,然后是安装的各种应用程�序。操作系统是裸机上的第一层软件,是对硬件功能的首次扩充。
引入操作系统的目的:
- **接口。**提供一个计算机用户与计算机硬件系统之间的 接口;
- 控制资源。有效地 控制和管理 计算机系统中的各种软件 / 硬件资源。
- 工作流程。合理地组织计算机系统的 工作流程,以改善系统性能。
问题:操作系统的功能和服务
五大基本功能:处理器管理、存储器管理、设备管理、文件管理、用户接口。
- 处理器管理:处理器的分配和运行以 进程 为基本单位,对处理器管理就是对 进程的管理
- 进程控制:负责进程的创建、撤销、状态转换
- 进程同步:对并发执行的进程进行协调;
- 进程通信:负责完成进程间的信息交换
- 进程调度:按一定算法进行处理器分配(7)
- 存储器管理:对内存进行分配、保护、扩充。
- 内存分配:按一定策略为每道程序分配内存;
- 内存保护:保证各程序在自己的区域内运行,而不相互干扰。
- 内存扩充:借助虚拟存储技术,获得增加内存的效果。
- 设备管理:对计算机系统内的所有设备进行管理。
- 设备分配:采用缓冲技术、虚拟技术,使设备与主机并行工作。
- 设备传输控制:实现物理 I/O,即启动设备、中断处理、结束处理等。
- 设备独立性:用户程序中的设备与实际使用的物理设备无关。
- 文件管理:对文件系统的管理:
- 文件存储空间管理:合理的分配与回收
- 目录管理:提供科学的数据结构,实现高效检索。
- 文件操作管理:完成文件的读写操作。
- 文件保护:解决文件的共享、保密、保护问题。
- 用户接口
- 命令接口:提供一组命令供用户控制自己的作业。
- 程序接口:也称 系统调用。用户可在程序中使用这组系统调用命令,向操作系统提出:使用外设、申请分配内存、磁盘文件读写等操作。
- 图形接口:也就是图形化命令接口。
问题:操作系统的发展 / 分类
- 手工阶段:纸带机。人机速度矛盾。
- 批处理阶段:
- 单道批处理(脱机输入输出技术)
- 缓解人机速度矛盾。资源利用率低没解决。
- 多道批处理(操作系统雏形)
- 提高资源利用率(多道程序并发执行)。没有人机交互。
- 单道批处理(脱机输入输出技术)
- 分时操作系统(cpu 运行分时间片,任务轮流上 cpu 处理)
- 提供人机交互。不能优先处理紧急任务。
- 实时操作系统:
- 硬实时系统(严格在规定时间内完成处理)
- 软实时系统(可偶尔违反时间限定)
- 解决了优先处理紧急任务问题。
- 网络操作系统
- 分布式操作系统
- 多个分散的处理单元,通过网络连接而成的系统。可以动态的分配任务。
问题:操作系统的运行环境 / 运行机制
对处理器的执行状态,分为两种:
- 核心态:管态、系统态。操作系统管理程序执行时的状态。具有较高特权,能执行一切指令,能访问所有寄存器、存储区。
- 用户态:目态。用户程序执行时机器的状态,权限较低。用户态程序不能直接调用核心态程序,而是通过执行访问核心态的命令,引起 中断,由中断系统转入操作系统内的相应程序。
总结:用户进程在用户态工作、系统内核在内核态工作。
特权指令:只能由操作系统内核使用,不允许用户直接使用。如 I/O 指令、设置中断屏蔽指令、清内存指令、存储保护指令、设置时钟指令。
操作系统的内核:内核指令在核心态工作。
- 与硬件紧密的模块:时钟管理、 中断处理、设备驱动
- 时钟管理:操作系统通过时钟管理,向用户提供标准的系统时间。通过时钟中断的管理,实现进程切换、时间片轮转调度。
- 中断机制:内核负责保护和恢复中断现场的信息。
- 运行频率较高的程序:进程管理、存储器管理、设备管理。
问题:什么是中断 / 异常
中断系统的作用:
- 让操作系统的内核强行夺回 CPU 控制权;
- 使 CPU 从用户态变为内核态;
中断 / 外中断
来源:中断信号来自 CPU 外部,与当前指令无关。中断是在用户态触发的。
检查时机:CPU 在执行每个指令的周期末尾,CPU检查是否有外中断信号。
- 时钟中断:时间片到期,需要切换应用进程。将正在执行的应用进程暂停,调用新进程
- I/O 中断:用户进行 I/O 相关操作。正在执行的进程需等待用户输入,因而中断当前操作,等待资源到达。
- 硬件中断:硬件故障引起的中断,比如打印机突然没电
- 程序中断:程序在执行过程中的 一般中断。比如上文的 I/O 中断。
异常 / 内中断
来源:中断信号来自 CPU 内部,与当先执行的指令相关。
检查时机:CPU 在执行指令时,随时检查是否有异常发生。
- 陷阱 / 陷入 / trap:应用程序故意引发。
- 故障 / fault:进程的条件错误、条件不满足、CPU修复故障后继续。(缺页故障)
- 终止 / abort:致命错误,无法修复,终止进程。(整数除 0、非法使用特权指令)
通常异常会引起中断,而中断未必是异常引起。
问题:什么是系统调用
系统调用是操作系统对应用程序/程序员提供的接口,API (Application Programming Interface)。
系统调用和中断在用户��态发生,在核心态处理。
通过系统调用,可以把程序的请求传给内核,内核在完成相应的处理后,再返回给程序。
- 用户进程在 用户态,通过 陷入 指令,执行系统调用,让进入操作系统的系统内核。
- 此时操作系统转化为 内核态。系统内核执行相应的 系统调用函数,然后将处理结果返回给用户进程。
- 此时操作系统再切换为 用户态,用户进程拿到结果,程序继续运行。
系统调用的功能有:
- 进程管理、文件操作、设备管理、主存管理、进程通信、信息维护。
第二章:进程管理
问题:什么是进程
是系统进行资源分配、运行调度的基本单位。
通过进程、程序来定义进程:
程序:静态(静止的有序代码)、永久(在外存中存放)、一个程序可以产生多个进程。
进程:动态(在执行中的程序)、暂时(在内存中运行)、一个进程可以调用多个程序。
通过引入进程的原因来定义进程:
- 下一个问题
从进程的 5 特征来定义进程:
- 动态性。最基本特性,执行的过程是动态可控、可调整的。
- 并发性。多个进程可同时存在内存中,可同时运行。
- 独立性。进程是独立运行、资源分配和调度的基本单位。
- 异步性。各个进程的各自独立、不可预知的速度推进。
- 结构性。每个进程:PCB + 程序段 + 数据段组成。
- PCB 进程控制块:唯一标识进程、存储控制信息、资源分配信息等。
- 程序段:程序的指令代码。
- 数据段:运行中需要的、产生的数据。
问题:为什么引入进程
程序的执行是顺序的,具有 3 个特性:
- 顺序性:处理器的操作严格按照程序的规定顺序执行。完成当前操作才做下一个操作。
- 封闭性:程序一旦开始运行,独占系统的所需资源,这些资源只有本程序才能改变。
- 可再现性:程序执行时的初始条件、执行环境相同,重复执行时,结果一定相同。
当操作系统引入 并发:
程序的并发执行:若干程序同时在系统中运行,这些程序的执行在时间上是重叠的,即一个程序的执行尚未结束,另一个程序的执行已经开始。
- 优点:提高系统的处理能力和资源利用率。
- 可以合理的分配: I/O 资源、网络资源、CPU 处理资源、磁盘读写资源等。
这导致了程序失去了特性:
- 间断性。程序在并发执行时,相互是制约关系,在资源共享时,程序常间断执行。
- 失去封闭性。程序在执行时,必然受到其他程序的影响,资源不是独立占据并使用的。
- 不可再现性。程序并发执行时,失去了封闭性,每次执行环境不同,结果也可能不同。
当操作系统引入 进程:
为了使程序在并发时保持封闭性和可再现性,需要对资源共享进行更合理的调配。
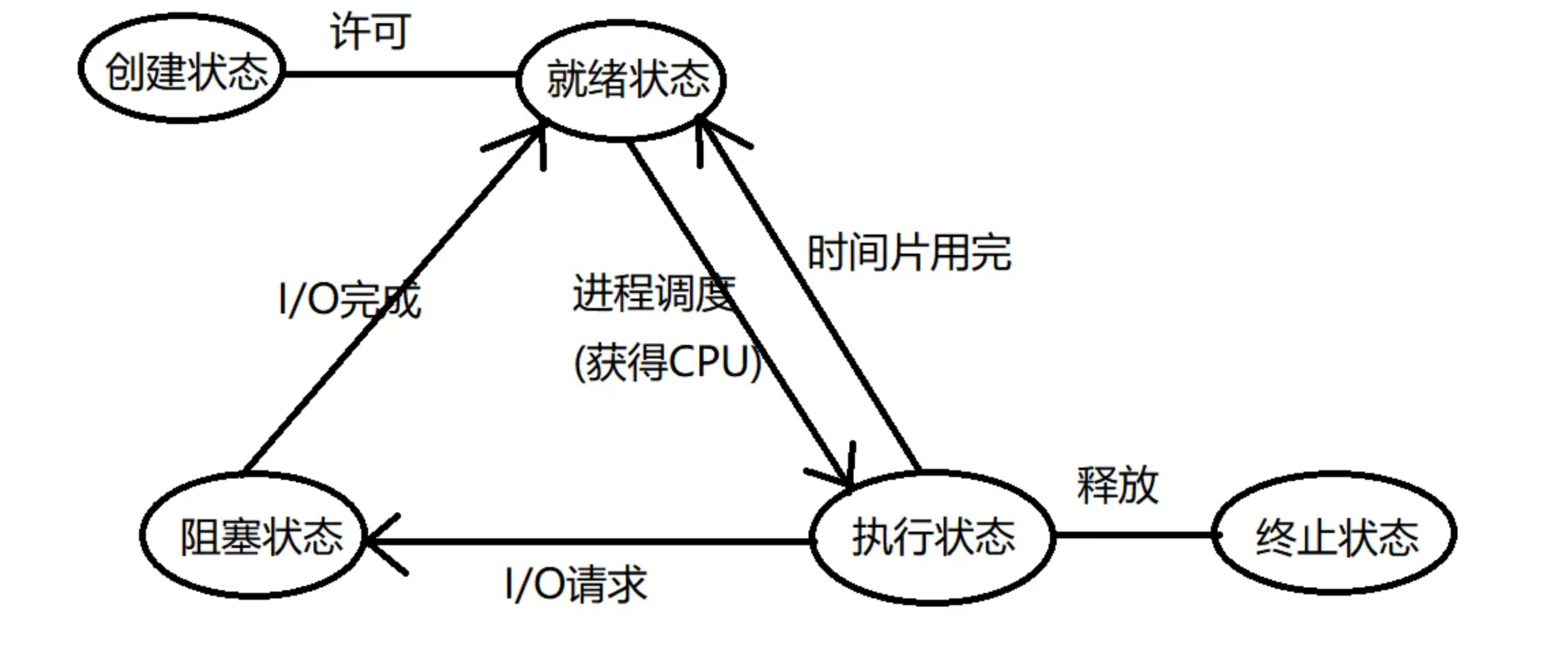
问题:进程的状态与转换
5 + 2 种状态:
-
正常流程:创建态 ➡️ 就绪态 ➡️ 运行态 ➡️ 终止态;
-
发生阻塞:阻塞态;
-
两个挂起:阻塞挂起、就绪挂起;
创建态:进程正在创建的状态。创建 PCB,填入信息 ➡️ 分配需要的资源。
就绪态:进程已经获得除 CPU 以外的所有资源,一旦获得 cpu 资源,就可以立即执行。
执行态 / 运行态:进程在 cpu 上执行时的状态。
阻塞态 / 等待态:进程因发生事件而 暂停,无法执行的状态。通常在等待资源。
终止态 / 结束态:回收进程的资源 ➡️ 撤销 PCB。正常执行完毕,也有可能异常退出。
挂起:排队的过程。从内存调入外存。进程映像放在外存中。
5 状态模型:
7 状态模型
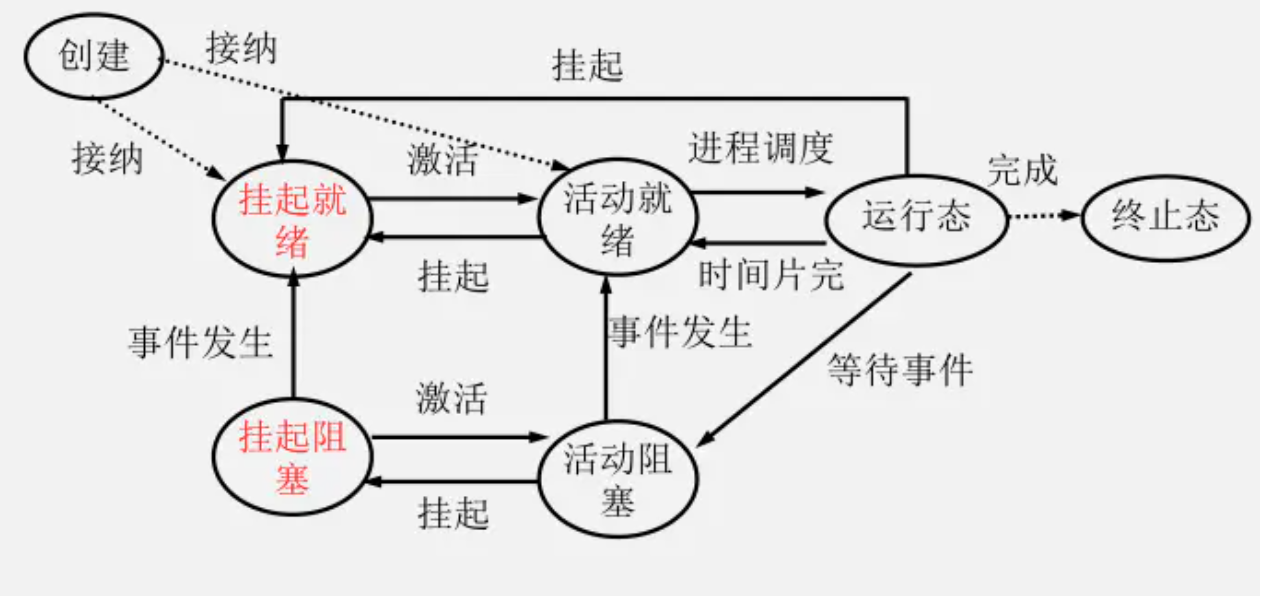
总结:
执行态 可以切换到:
- 阻塞状态:是因为请求并等待事件发生
- 就绪状态:是因为时机片用完、抢占式调度中有优先级任务需要执行。
- 终止状态:进程执行完毕、异常中断,需要销毁。
只有 就绪态,可以切换到 执行态。
问题:🌟 进程的控制/进程的通信/线程的通信
💊 进程的控制
概念:实现进程的创建、状态转换。通过 原语 实现控制,本质是关 / 开中断实现。
原语的工作:
- **进程的状态切换。**更新 PCB 信息(修改进程运行状态、保存/恢复进程运行环境);
- **进程的阻塞 / 唤醒。**将 PCB 插入合适队列(就绪、阻塞等);
- **进程的创建 / 撤销。**分配 / 回收资源(进程是否撤出/放入内存);
原语的内容:
- 阻塞原语:P原语。进程 主动调用,并切换。(运行 ➡️ 阻塞)
- 唤醒原语:V原语。进程被动切换。(阻塞 ➡️ 就绪)
🌟 进程间的通信
低级通信方式
-
锁机制
- 进程要更改共享数据时,先锁定资源,独占访问权。直到访问完毕后解锁,其他的进程才能再次锁定该资源。互斥锁保证每次只有一个进程进行写入操作,从而保证多线程情况下数据的正确性。
-
P 原语、V 原语(信号量):实现进程的同步、互斥
高级通信方式
-
共享存储
- 一个互斥访问的共享存储区。
-
管道通信
- 管道为一个共享的、互斥访问的特殊共享文件。
- 一个管道:半双工通信。两个管道:全双工。
- 管道中必须全满 / 全空,才可以继续操作(读/写)。
-
消息传递
- 消息为单位通信(消息头/消息尾)。通过系统的 ‘发送/接受原语’ 实现。
- 直接通信方式:直接挂到接收方的消息队列中
- 间接通信方式(信箱):通过信箱中间体。
-
socket
- 它可用于不同机器间的进程通信
🌟 线程间的通信
-
锁机制
- 某线程要更改共享数据时,先锁定资源,独占访问权。直到访问完毕后解锁,其他的线程才能再次锁定该资源。互斥锁保证每次只有一个线程进行写入操作,从而保证多线程情况下数据的正确性。
-
P 原语、V 原语(信号量):实现线程的同步、互斥
- 信号量:资源统计 + 等待队列。通过原语的 开、关 中断,一气呵成,实现上锁🔒的不可被打断。
-
Java中有一些包支持线程间通信:Condition 条件对象、event 事件对象。
问题:🌟 为什么要引入线程
区�分:线程是 CPU 调度的基本单位、进程是资源分配的基本单位。
进程的特点:
- 进程是一个用有资源的独立单元
- 进程同时又是一个可以被处理器独立调度和分配的单元。
存在的缺点:
- 操作系统还需要进行:进程创建、撤销、状态切换。进行这些操作时,需要为进程分配资源和回收资源,同时要保存进程现场信息,付出了较大时空开销。
解决思路:
- 在系统中尽量少的创建进程、尽量低频的切换进程。
解决方式:
- 将进程的两个特点切分,让进程只完成第一个任务:资源独立的单元,线程去完成第二个任务:CPU 调度的基本单位。
总结:
引入进程的目的,是让多个程序可以并发执行,以改善资源利用率,提高系统吞吐量。
引入线程的目的,是减少程序并发执行时所付出的时空开销,使操作系统更好的并发性。
- 线程是进程内相对独立的、可调度的执行单元。线程自己基本不拥有资源,只在运行时占用一点资源(程序计时器、寄存器、栈),同一个进程内的资源,线程相互共享。
同一进程内的线程:
- 内存地址共享。
- 资源共享。
- 线程间的通信无需经过操作系统。
- 线程的切换,不会倒车进程的切换。
问题:线程的实现
用户级线程:不需要操作系统。进程通过线程库控制线程。
- 优:线程调度不需要用户态 / 内核态切换。速度极快。
- 缺:一个线程阻塞,整个进程等待(时间片是分配给进程的,CPU看不到线程,不知道阻塞,不会切换线程)
内核级线程:操作系统实现线程,完成线程的创建和销毁工作。
- 优:一个线程阻塞由于 IO 阻塞时,不影响其他线程运行(时间片是分配给线程的,CPU 可以感知到阻塞,然后主动切换)
- 缺:切换速度慢,依赖内核态。
两种组合:用户、内核都可以建立线程,各取优点。
- 一对一:一个用户级线程,映射,一个内核级线程
- 优:并发度高。线程都可以分配到CPU并发执行。
- 缺:开销大。操作系统管理线程太多。
- 一对多:多个用户级线程,映射,一个内核级线程
- 优:开销小。管理高效。
- 缺:并发度低。若一个线程阻塞,则无法调度其他线程,整个进程阻塞。
- 多对多:开销小,并发度高
问题:处理器的三级调度
调度是操作系统的基本功能。CPU 是计算机的首要资源,所以调度设计均围绕如何高效利用 CPU 资源而展开。异构作业从提交到执行,通常要经历多级调度。
- 高级调度(作业):在队列中挑选一个作业,外存进内存,添加资源 + 创建进程。
- 无 ==> 创建态 ==> 就绪态
- 中级调度(内存):队列中,外存进内存,挂起变就绪。
- 挂起就绪态 ==> 就绪态
- 挂起阻塞态 ==> 阻塞态
- 低级调度(进程):队列中,内存进 CPU。
- 就绪态 ==> 运行态
问题:🌟 调度算法 (7)
进程的调度策略
💊 进程调度的时机
- 进程主动放弃
- 进程执行完毕,终止进程。
- 进程主动阻塞,等待所缺资源,如 I/O 操作、网络资源。
- 进程被动放弃
- 时间片用尽。
- CPU 被抢占,高优先级进程在就绪态。
- 紧急事件处理,如 I/O中断,杀进程。
抢占式:如果有高优先级进程进入就绪态,就会让正在处理的进程挂起。
非抢占式:不会让正在处理的进程挂起,而是等待执行完成,或主动进入阻塞态时,再执行。
💊 批处理系统 (3)
先来先服务 FCFS(作业调度、进程调度)
-
按照队列的思路,先排队的先执行,没有优先级概念。
-
优:公开、实现简单。进程不会饥饿。
-
缺:对长作业有利,短作业不利。短作业周转时间长,等待的时间过多。
-
短作业优先 SJF(非抢占)(作业调度、进程调度)
-
在挂起就绪的队列中,周期性评估可以最短完成的作业,然后优先让它们执行。
-
优:平均等待时间、平均周转时间最短。
-
缺:长作业不利,会饥饿
-
高响应比优先 HRRN( only 作业调度)
综合了任务的等待时间和预估运行时间,形成相应比公式。
-
响应比 =(等待时间 + 预估运行时间)/ 预估运行时间 >= 1
-
优:综合优点:综合短作业优先(预估运行时间)、先来先服务(等待时间) 避免缺点:防止长作业饥饿(等待时间长,则优先服务)。
-
缺:响应比的计算需要开销。
💊 实时操作系统 (4)
时间片轮转(抢占)(only 进程调度)
所有进程按照先来先服务进入队列,CPU 资源按照时间片划分,到时间后就挂起当前的进程,切换下一个进程进场使用 CPU 资源。
-
优:公平、响应快、适用于分时操作系统。所有进程都不会饥饿。
-
缺:进程切换频率高,状态切换需要开销。不能区分任务的紧急程度。
优先级调度(抢占 / 非抢占)(作业调度、进程调度)
-
根据系统需求,可以对任务进行优先级划分。然后高优任务先执行。
-
优:区分紧急程度,适用于实施操作系统。灵活调整优先级偏好。
-
缺:高优先级过多,低优先级的进程就会饥饿。
-
多级队列调度(非抢占)(进程调度)
- 将等候的进程划分多个队列,每个队列都采用各自的调度算法。
多级反馈队列调度(抢占)(进程调度)
-
多级队列:依然划分多个队列,每个队列优先级从高到低,时间片从小到大。
-
每个队列:队列内统一按照 先来先服务。
-
当新进程进入调度时,首先放入第一个队列(高优 + 短时)的队尾,等待执行。如果在划分好的时间片内没有执行完毕,则重新放入第二个队列的队尾。以此类推。最后一个队列无法再往下分,则使用 时间片轮转调度算法。
-
优:公平(先来先服务),新进程快速响应(高响应比优先),短进程快速处理(多作业优先),灵活偏好�(优先级)
-
缺:会饥饿(如果第一个队列没执行完,会一直运行第一个队列的进程)
-
问题:🌟 进程的同步 / 互斥
同步和互斥的区别:
-
同步,直接相互制约:有先后次序的需求,不同类型的进程。
-
互斥,间接相互制约:有争用资源的需求,相同类型的进程。
同类进程即为互斥关系、不同类进程即为同步关系。
- 消费者和生产者就是同步关系、消费者和消费者就是互斥关系。
互斥存在临界资源:
- 临界资源:同时只允许一个进程使用的资源。入打印机、绘图机等。
访问临界资源的过程:
进入区:检查是否可进入,上锁🔒的代码,对即将进入的进程添加访问标记。
临界区:临街段,进程中访问临界资源的代码。
退出区:解锁🔓的代码,对访问结束的进程删除访问标记。
剩余区:其余代码,进程中除上述 3 部分以外的代码。
![临界区互斥-来源参考[3]](/assets/images/1fa1353e587e4fe8ab0967538699492d~tplv-k3u1fbpfcp-zoom-in-crop-mark:3024:0:0:0-e7ff4a20fd3ccd76d8c424bf5ea5c27a.awebp)
互斥的原则(4)
- 空闲让进:临界区空闲,则允许进程访问。
- 忙则等待:临界区占用,则禁止其他进程访问。
- 有限等待:不会饥饿,有限时间内,一定会进入临界区。
- 让权等待:不满足条件的进程,不会盲等,占用CPU资源。
问题:🌟 互斥的实现(锁)
有 4 + 2 种方式:核心思想就是如何 加锁。
软件方式 - 单标志法 - 公用 turn 标志进程号。谁先进去,谁就修改一下 turn。 - 缺:进入时只检查,不上锁。退出时给对方解锁,给自己上锁(转交使用权) - 不满足:空闲让进。必须进程交替进入。
- 双标志先检查法
- 数组 flag[ false, false ]。先检查,后上锁🔒。进程只修改自己的标志。
- 缺:检查和上锁无法一气呵成。
- 优:解决空闲让进。不需要交替进入
- 不满足:忙则等待。若同时检查通过,会同时进入。
- 双标志后检查法
- 数组 flag[ ]。先上锁🔒,后检查。进程只修改自己的标志。
- 缺:检查和上锁无法一气呵成。
- 优:解决忙则等待。先上锁确保不会同时进入。
- 不满足:空闲让进 + 有限等待。同时上锁,都进不去,产生饥饿。
- Peterson 算法(皮特森算法)
- 算法 1 和 3 的结合。flag[false, false ] = 希望进入;turn = 谦让。
- 利用 flag[] 解决资源互斥访问、利用 turn 解决进程饥饿。比如 p0 进程想要读区资源,会把自己位置的 flag[0] 置为 true,然后把 ture = 1 谦让对方先执行。接下来判断:
while(flag[1] && turn = 1)就一直等待。直到 p1 的 flag 位置调整为 false,或 turn 指向自己 0。- flag[1] 为真表示 p1 希望访问,turn 为 1 表示 p1 可以访问。
- 利用 flag[] 解决资源互斥访问、利用 turn 解决进程饥饿。比如 p0 进程想要读区资源,会把自己位置的 flag[0] 置为 true,然后把 ture = 1 谦让对方先执行。接下来判断:
- 进入区:表明想用 ➡️ 主��动谦让 ➡️ 检查(对方是否想进,我是否谦让)
- 检查:对方想进 且 我主动谦让,则循环等待。 while ( flag[1]=true && turn==1 )
- 优:综合上面三种方法,解决:空闲让进、忙则等待、有限等待。
- 缺:不满足让权等待(四个方法都不满足)一直占用 CPU。
- 算法 1 和 3 的结合。flag[false, false ] = 希望进入;turn = 谦让。
硬件方式
- 中断屏蔽法 和 硬件指令法
- 开/关中断指令,利用 **原语**,确保检查和上锁一气呵成,不被打断。
- 优:简单、易于实现。
- 缺:while 一直循环等待,违背让权等待,产生饥饿。
问题:信号量
引入信号量:
解决进程互斥,上述提到了 6 种方式。软件方法存在算法复杂、效率不高、违背 忙则等待 原则的问题;硬件方法存在违背 让权等待 的缺点。
信号量是一种同步机构,一种协调进程间共享资源访问的⽅法。
- 解决了让权等待,忙则等待,不会浪费 CPU 资源。
解决方式:通过原语的 开、关 中断,一气呵成,实现上锁🔒的不可被打断。
// semaphore 信号量 = 资源数量统计 + 等待队列
const s = {
count: 10,
queue: []
}
// P 操作:🔒 + 申请 / 使用资源
const wait = (p) => {
s.count--;
if (s.count < 0) {
block 原语 // 阻塞该进程: 进程挂起到阻塞队列
s.queue.unshift(p); // 将该 p 进程插入等待队列 s.queue
}
// p进程使用资源
}
// V 操作:🔓 + 释放/ 产生资源
const signal = (p) => {
s.count++;
if (s.count >= 0) {
s.queue.pop(); // 队列中取出最后一个进程p
weakup 原语 // 将p放入就绪队列,等待执行
}
}
信号量的使用
实现进程同步:先 V 后 P。
- 初始资源值为 0。先生产资源、再消费资源。
举例:P1 中有语句 S1,P2 中有语句 S2。要求 S1 必须在 S2 之前执行。
// 设置信号量初始值
semaphore.count = 0;
function P1() {
// ...
S1;
V(count);
}
function P2() {
// ...
P(count)
S2;
}
实现进程互斥:先 P 后 V
- 初始资源值为 1。先执行的进程,优先消费资源,后执行的进程只能等待。
// 设置信号量初始值
semaphore.count = 1;
function P1() {
// ...
P(count);
// P1 的临界代码
V(count);
}
function P2() {
// ...
P(count);
// P2 的临界代码
V(count);
}
死锁、饥饿、活锁、死循环的区别
- 死锁:(争用公共资源) 多个进程之间,相互竞争资源,陷入无期限地等待其他进程占有的资源,都在阻塞等待。
- 饥饿:(优先级问题) 某一个进程,因任务调度问题,长期得不到资源而阻塞。(短作业优先) 如果长期无法执行,该进程则处在 饿死 状态。
- 活锁:在忙时等待条件下发生的饥饿,称之为“活锁”。例如不公平的互斥算法,让某些进程一直在等待被占用的资源,这实际上也是优先级的问题。
- 死循环:某一个进程,在 while、for 等逻辑内,跳不出循环。(P V 操作)
💊 死锁 / 饿死的区别
共同点:死锁 / 饿死都是因 竞争资源 而引起的。
不同点:
从所争资源考虑:
- 死锁:死锁进程等待的是永远也不会释放的资源。
- 饿死:饿死进程等待的是会释放、但永远也不会分配给自己的资源。
从进程状态考虑:
- 死锁:一定发生了循环等待 (哲学家困境),可以通过资源分配图检测出。
- 饿死:没有循环等待,无法通过资源分配图检测。
从涉事人员考虑:
- 死锁:一定是两个以上的进程,都发生了死锁。
- 饿死:一个进程就可能被饿死。
问题:什么是死锁
通过 哲学家问题 引发的死锁。
- 5 个哲学家围坐一张桌子。桌子上有 5 根筷子,分别放在每个哲学家之间。哲学家的动作有:思考、进餐两种。进餐时需要同时拿起左右手的两根筷子,思考时需要将左右手的筷子放回原处。
- 这就是并发进程执行时,处理临界问题面临的困局。筷子是临界资源,不能被两个哲学家一起使用,仅此用一个信号量数组来表示筷子。
- 死锁僵局:当 5 个哲学家同时饥饿而各自拿左边的筷子时,会导致 5 根筷子均被占用,当他们要拿右手筷子时,会因没有筷子而无限等待,但是又不愿放弃左手的筷子,这就是所谓 让权等待 原则。
解决方式:规定奇数号的哲学家先拿左边筷子,然后拿右边筷子;偶数号的哲学家相反。
定义:当多个进程因竞争系统资源或相互通信,而处于永久阻塞状态。若无外力作用,僵局无法打破,这些进程都会陷入无期限地等待其他进程占有的、自己无法得到的资源。
问题:死锁产生的条件
围绕资源,死锁产生的原因有两点:系统资源不足 (根本原因)、进程推进顺序不当。
死锁产生必须满足 4 个条件:
- 互斥条件:进程间的资源必须互斥。一段时间内某种资源仅为一个进程所占有。
- 不剥夺条件:进程掌握的资源无法强制剥夺收回,只能由进程使用完后,主动释放。
- 请求和保持条件: 进程已经申请到一部分资源,在等待分配其他需求资源的同时,继续占有已经分配到的资源,不释放。
- 环路等待条件:进程间发生了循环等待链条,也就是哲学家困境。需要的资源被其他进程持有,这样形成了一个资源的循环等待链。
问题:死锁的处理
主要有 4 种思路:
- 不处理:鸵鸟算法。
- 预防死锁:静态处理,预先破坏产生死锁的 4 条件中的某些条件。
- 避免死锁:动态处理,在分配资源过程中,用算法(银行家算法),防止发生死锁。
- 死锁的检测和解除:发生死锁后解决。通过系统检测,及时发现死锁,然后解决。
问题:死锁的预防 / 避免
预防死锁 和 避免死锁 是不一样的:
- 两种都在死锁产生之前,实施措施,不同的是:
- 死锁预防 是非常严格的,通常会对系统并发性造成很大副作用,同时也不需要再添加额外的算法去避免死锁。
- 死锁避免 对系统附加条件相关宽松,有利于并发,但在资源被分配出去之前要计算分配之后系统是否安全,有额外的算法开销。
💊 死锁的预防
只需破坏产生死锁的 4 个必要条件之一即可:
- 破坏互斥:
- 让资源不再互斥:临界资源改为共享资源(SPOOLing技术)
- 缺点:有些资源(🖨️)无法变为共享资源,可行性低。
- 破坏不可剥夺:
- 当进程已经获得一部分资源,而剩余资源无法满足时,有两种思路:
- 强制释放自己的所有资源;
- 按照优先级,剥夺别人的资源(优先级)。
- 缺:算法开销大,有些进程会饥饿,被随意剥夺资源可能会造成严重后果。
- 当进程已经获得一部分资源,而剩余资源无法满足时,有两种思路:
- 破坏请求和保持:
- 静态分配的办法,进程一次性申请全部所需资源,预先分配好全部资源,才运行
- 缺:资源利用率低,有些进程迟迟得不到资源,会饥饿。
- 破坏循环等待:
- 有序资源分配。资源按不同类型编号;进程申请资源必须从小到大,有序申请。
- 比如给打印机为1,磁带机为2,进程必须从1到2申请,不能反着申请。
- 缺:不便于新增设备,资源利用率低,编程困难。
💊 死锁的避免
动态方法:在系统进行资源分配前,先计算资源分配的安全性。若此次分配不会导致系统进入不安全状态,则分配,否则不分配,进程继续等待。
- 安全状态:系统不会死锁,则该序列为安全序列。
- 不安全状态:系统不稳定,有可能会死锁,也有可能会回到安全状态。
- 安全性算法:寻找安全序列 —— 银行家算法 🏦
💊 银行家算法
通过多个进程资源分配表:
| 进程最大需求量 | 已经分配量 | 还需要的量 | 系统剩余资源 | 申请的量 |
|---|---|---|---|---|
| max | Allocation | Need | Available | Reques |
步骤: 1. 检查申请是否超过这个进程之前申请的最大需求量; 1. 检查系统剩余可用资源是否满足; 1. 模拟分配,使用安全性算法,寻找安全序列(就是资源先给谁,后给谁)
问题:死锁的检测 / 解除
💊 死锁的检测
数据结构:资源分配图 (有向图)
- 两种结点:进程结点(一个进程)、资源结点(一类资源,有数量)
- 两种边:申请边、分配边
检测方式:
- 找到可能形成孤立的、 不阻塞的进程结点,即它已经获得了所有所需资源,可以继续运行知道进程执行完毕,然后释放持有资源。
- 假设该可能孤立的进程释放资源后,消除其持有资源的边,简化资源分配图。
- 重复这一过程,直到不可再简化:
- 若能消除所有边 ➡️ 可完全简化的,没有死锁
- 不能消除所有边 ➡️ 发生死锁
💊 死锁的解除
资源剥夺法:从其他进程中抢占所需资源,挂起这些进程,让自己解除死锁状态。
撤销进程法:终止某些进程,让它们归还占用资源,然后分配给其他进程,解除死锁状态。
进程回退法:让一些进程回退到系统不死锁的状态,进程自愿释放资源,而不是剥夺。这要求系统保持进程的历史信息,设置还原点。
问题:并行 / 并发的区别
并发:一条赛道,同步执行。并发是单核 CPU 的一种调度算法。通过时间片轮转,给不同的进程都有公平参与执行的机会,不会导致进程饿死。因切换速度足够快,宏观上看似多个进程在同时执行。
并行:多条赛道,同时执行。就是多核 CPU,��可以各自管理,真正的同时执行多个进程。
第三章:内存管理
问题:内存管理的功能
- 内存空间分配 / 回收:连续 / 非连续 分配。
- 扩充内存:对内存空间的扩充,采用 覆盖、交换、虚拟 等方式。
- 地址变换:相互转换:程序中使用的逻辑地址,和内存中实际的物理地址
- 内存保护:(两种寄存器) 保证不同作业互不干扰,防止作业 A 发生错误而破坏作业 B
问题:内部碎片 / 外部碎片
内部碎片:已经分配给作业,但不能被作业利用的内存空间。
外部碎片:还没有分配给作业,但由于碎片太小而无法分配给作业的内存空间。
通俗说,作业占用的内存空间,没有装满,有剩余就是内部碎片。有些内存区域无法分配给作业,就是外部碎片。
问题:内存的分配方法
内存的空间分配与回收,分为 3 个思路�:
- 连续分配 3 :
- 单一连续分配
- 固定分区分配
- 动态分区分配
- 非连续分配 3:内存可连续(分页)、可离散(分段)
- 基本分页存储管理:基本、快表、二级页表
- 基本分段存储管理
- 基本段页式存储管理
- 虚拟内存技术
- 请求分页存储管理
问题:内存的连续分配 (3)
单一连续分配 (单道程序)
最简单的分配方式,系统区是内存低地址部分,给系统使用。
- 内存分为:系统区 + 用户区。
- 只支持一个程序进入,静态分配,采用覆盖技术扩充内存。
- 优:管理简单,无外部碎片。
- 缺:单用户、单操作系统,有内部碎片。
固定分区分配 (多道程序)
内存事先划分大小不等的固定区域,在运行时不能更改。每个分区可以装入一道程序。
- 内存划分:系统区 + 大小不一 (相等) 的固定分区,不再更改。
- 设置分区说明表:分区号(隐含)、容量、起始地址、状态(是否分配)。
- 程序装入时:找到合适大小的分区装入,不满足则拒绝装入,装入采用静态重定位方式
- 优:支持多道程序,无外部碎片。
- 缺:有内部碎片,分区固定灵活度不高,利用率低,无法多进程共享一个内存区。
动态分区分配 (多道程序) / 可变式分区分配
-
内存划分:系统区 + 用户区。不预先划分,进程要多大,划分多大。
-
一表一链:‘空闲分区表’ + ‘空闲分区链’ :分区号、容量、起始地址、状态。将空闲的区域通过链表形式串联起来。
-
采用动态分区分配算法 (4):(下文) 首次、最佳、最差、邻近
-
内存回收:内收内村后,会更新链、表信息。合并问题连续的内存空间。
-
优:无内部碎片,灵活度,利用率高
-
缺:有外部碎片,可以用紧凑技术解决。动态算法有开销。当有大作业来到时,其存储空间的申请可能会得不到满足。
-
问题:动态分区分配算法
首次适应算法:(First Fit,FF)—— 最佳
把空间分区按照地址递增的次序用链表串联。进程分配内存时顺序查链表,找到第一个符合的,空间足够大的分区进行分配。把该分区划分出和进程所需空间相等的内存,剩余内存用链表继续串联。
-
优:综合性能最佳,算法开销小,不需要重排列分区。
-
缺:在低地址区,小碎片 (外部碎片) 会越来越多,从低地址查表,浪费开销。
邻近适应算法:(Next Fit,NF)
在首次适应算法的基础上,把队列改成循环队列。这样不用每次从队首开始查找,而是从上次查找分区位置开始查找。
-
优:不需要每次从低地址小分区开始查找,提升速度、算法开销小。
-
缺:高地址的大分区可能储备不足,大进程得不到满足。
最佳适应算法:(Best Fit,BF)
链表按照容量递增顺序组织。从小到大查表,优先用最小的。
-
优:保留许多大分区满足大进程需求
-
缺:产生许多难以利用的小碎片 (外部碎片),算法开销大,需要频繁重排列链表。
最差适应算法:(Worst Fit,WF)
链表容量递减顺序。从大到小查表,优先用最大的。
-
优:减少小碎片的产生
-
缺:大分区不足,大进程得不到满足,算法开销大,频繁重排列链表。
问题:解决内存中的碎片问题
拼接 / 紧凑 / 紧缩技术:已分配分区移动到内存一端,让碎片可以合并。
拼接时机:
- 出现分区回收时,就拼接(过于频繁)。
- 有作业找不到合适空间 + 内存碎片容量足够时,拼接。
- 缺点:系统开销大
问题:🌟 基本分页存储管理
如果内存连续分配,一定会产生外部碎片问题,尽管拼接技术可以解决,但算法复杂,大规模移动内存代价过高。
基本思想:进程分页、内存分块。各页面可离散的放置到各内存块中。
- 页、页面:进程被划分成若干大小相等的区域。
- 查找方式:页号 + 页内偏移。也就是页面的起始地址 + 长度。
- 块、物理块:内存被划分成与页面大小相等的区域。
- 页框:与页面大小相等的物理块。
- 页表:存放在内存中。数组:页号 (隐含) + 块号。将页面和物理快一一对应。
逻辑地址 到 物理地址 的转换:
通过分页查找物理地址 (数据),需要 两次内存访问:
- 访问页表。内存中查找页表:页号 + 页内偏移,找到对于物理块号,计算物理地址。
- 访问数据。通过物理地址,访问内存,取出数据。
💊 改进:具有快表的地址变换机构
计算机硬件中,处理速度越快的设备,价格也昂贵。
- 存储设备中,越接近 CPU 的设备速度越快,但其内存空间也越少,所以要更珍惜使用。外存、内存、高速三级缓存、高速二级缓存、高速一级缓存。
通常改进的思路,就是提取 热点项目,然后存放在更快一级的内存设备中。
- 达到以「价格 + 空间」换「速度」的效果。
若页表全部放在内存中,则存取一个数据或一条指令只要少访问两次内存,速度有点慢,引入快表。
- 局部性原理:热内存。即在⼀段时间内,整个程序的执⾏仅限于部分代码区。执⾏所访问的存储空间也局限于某个内存区域。
- 时间局部性:部分代码的执行,集中在较短的时期内。
- while 循环,一段时间反复使用。
- 空间局部性:部分代码的执行,集中在相邻的物理地址。
- 数组挨个赋值,相邻的单位会经常访问。
- 时间局部性:部分代码的执行,集中在较短的时期内。
快表 TLB:存储在 CPU 的高速缓存中,速度快,存放经常使用的页表项。
改进后,逻辑地址 到 物理地址 的转换:
- 查快表:若直接若命中,则可直接计算物理地址 3,否则查慢表;
- 进入内存查页表:找到物理块,然后更新快表;
- 快表更新:长时间不查找的表项删除;刚查找的表项添加。
- 计算物理地址。
- 进入内存,访问物理地址。
💊 改进:二级页表 / 多级页表
改进原因:
- 页表必须连续存放,单页表容易占用过大连续空间;
- 有些地址长时间不会访问,所以整个页表无需全部常驻内存。
改进效果:
- 带个页表的长度大大减小,所以访问速度得到提升。
- 但多个页表,占用空间提升。
- 二级页表,还有三次内存访问。
改进后,逻辑地址 到 物理地址 的转换:
- 访问内存,查外层页表:找到内层页表地址
- 访问内存,查内层页表:找到物理块号
- 计算物理地址
- 访问内存,访问目标物理地址。
💊 优缺点:
优点:内存利用率高、实现了离散分配、便于存储访问控制、无外部碎片。
缺点:需要硬件支持(尤其是快表)、内存访问下降(二级页表)、有内部碎片。进程是无逻辑的等量分页,所以不方便程序内数据共享。
问题:🌟 基本分段存储管理
分页管理��,着重对内存空间进行切分。而分段管理是对进程 / 作业进行切分。一个作业通常是多个程序段 / 数据段组成的,程序员会按照逻辑对作业分段,每段有可识别的名称,根据名称访问相应的程序段或数据段。这样可以实现对相同逻辑的复用。
基本思想:内存分段。把内存按照程序自身的逻辑关系划分为若干段 (大小不一)。每段从 0 开始编址,一个段必须占据连续空间,但各段可以不相临。
段表:段号(隐含) + 段长 + 基址 (该段内存中的始址)。
- 段号:代表某个程序段;
- 段长:反应作业空间,该程序段占用内存的空间大小;
- 基址:反应内存空间,该程序段在内存中的起始位置。
逻辑地址 到 物理地址 的转换:
- 系统为每一个进程建立一个段表,
- 进入内存,查段表,找到对应段表项
- 计算物理地址
- 进入内存,访问目标物理地址。
💊 优缺点:
优点:便于程序模块化处理、便于动态链接和共享、无内部碎片。
缺点:需要硬件支持、有外部碎片、为满足分段的动态增长和减少外部碎片,要拼接(紧凑)技术。
💊 分段与分页相比:
-
分页:页,物理单位,有内部碎片,用户透明,进程地址空间一维:页地址。
-
分段:段,逻辑单位,有外部碎片,用户可见,进程地址空间二维:段名+段内地址
-
分段优点:段按照逻辑划分,方便信息的共享和保护(段内代码和数据可共享),段长过大的话,不容易找到内存和可放下的连续空间。
问题:🌟 基本段页式存储管理
思想:分段 + 分页
- 分段的优点:易于信息共享与保护
- 分页的优点:内存利用率高,无外部碎片;解决段长过大不易找连续空间。
一个进程:1 个段表 + n 个页表
- 分段:将程序的空间地址,按照程序逻辑划分若干段;
- 分页:各段中,划分若干相等大小的页;
- 内存:划分为与页相等的物理块,以物理块为进程分配内存。
创建的实体 :
- 段表:段号(隐含) + 页表长度 + 页表始址
- 页表:页号(隐含) + 内存块号
逻辑地址 到 物理地址 的转换:
- 访问内存,查段表:找到页表起始地址。
- 访问内存,查页表:找到物理块号。
- 计算物理地址
- 访问内存,访问目标物理地址。
⚠️ 3 次访问内存:段表、页表、访问物理地址
- 如果在页表中引入快表,可以一次命中,只 2 次访问。
💊 优缺点:
优点:上面有
缺点:内部碎片并没有做到和页式一样少。一个程序往往有很多段,平均下来段页式的内部碎片比页式还多。
问题:内存的扩充
覆盖技术 (早期操作系统)
- 一个大程序划分为若干‘覆盖’ = 程序段
- 内存中:一个固定区 (主程序)。不会掉入调出。存放最活跃的程序段。
- 内存中:若干覆盖区。互斥的 ‘覆盖’,可共享一个覆盖区,运行时动态掉入调出。
- 缺点:程序员需要声明覆盖结构,不透明,增加编程负担。
交换技术 (内存调度)
- 当缺页率频发、内存不足时,执行交换技术。
- 内存中:调出某些进程放到外存,保留PCB,移至挂起态。
- 外存中:设置文件区、对换区 (交换区)。对换区读取速度快,且有就绪挂起、阻塞挂起队列。
虚拟技术(后面的问题:虚拟内存)
问题:虚拟内存技术
引入原因,之前介绍的存储方式,有两个特点:
- 一次性:作业 / 程序全部装入内存后,才开始执行。
- 驻留性:作业 / 程序常驻内存,直到运行完全结束。
根据 局部性原理,程序在执行过程中,有写代码的使用较少(如错误处理),而有些代码需要较长时间的 I/O 处理,这些代码占用了很多内存,导致内存空间浪费。
虚拟内存:一种能够让作业 / 程序 部分装入,就可以运行的存储管理技术。
- 部分装入。在程序装入内存时,可以将程序的一部分放入内存,而其余部分放在外村,然后启动程序。程序在内存中 离散存储。
- 请求掉入。在程序执行过程中,当访问的信息不在内存时,再由操作系统将所需的部分调入内存。
- 置换功能。操作系统可以将内存中暂时不用的程序段,置换到外存中,腾出空间。
- 虚拟内存。从效果上看,计算机系统提供了一个比实际内存大的多的存储容量。
问题:请求分页存储管理
分页存储管理解决了内存中的外部碎片问题,但它要求程序需要一次性全部调入内存,导致不常用的代码块占据内存中。同时如果作业太大,也有可能无法完整放入内存中。
思路:进程分页 + 请求调页功能 + 页面置换功能
- 先将程序部分载入内存执行,当需要其他部分时,再调入内存。
- 部分装入、请求调入、值换功能、虚拟内存。
页表结构
| 页号(隐) | 物理块号 | 状态位 | 访问字段 | 修改位 | 外存地址 |
|---|
-
页号、物理块号:分页存储中原有的表项,反映进程页在内存中的位置。
-
状态位:判断是否在内存中,如果不在则发生 缺页中断。
-
访问字段:记录页面在一段时间内的访问次数,供值换算法参考。
-
修改位:页面调入内存后是否被修改过。当 CPU 以写方式访问页面时,调整修改位。
- 内存中的页面在外存上有副本,若页面没被修改,则该页面值换出时,可直接丢弃,减少磁盘写的次数。
逻辑地址 到 物理地址 的转换:
-
提取:逻辑地址 = 页号 + 页内偏移量;
-
判断:页号 < 页表长度 (页表寄存器),越界中断;
-
查快表:直接命中,则跳至 6;
-
查慢表:若不在慢表中,则执行:缺页中断 + 请求调页;
-
更新快表:更新快表信息;
-
修改页表:访问位 + 修改位(若数据修改);
-
计算地址:物理地址 = 内存块号 * 块大小 + 页内偏移量;
-
访存:访问内存中的目标物理地址。
缺页中断:
-
查找缺页:保留现场,外存中寻找缺页。
-
判断空间:如果内存已满,则执行:页面置换。
-
缺页调入
-
更新页表
⚠️ 缺页中断属于内中断:故障。
页面置换:
- 执行算法:执行对应的置换算法。
- 判断修改:判断该页有无修改,如果有,则把页面写入外存中,没有则直接丢弃。
💊 优缺点:
优点:离散存储,减少连续存储导致的外部碎片;虚拟存储,提高内存的利用率;
缺点:必须硬件支持 (缺页中断);会发生抖动现象 (页面频繁调入调出)。
问题:页面置换算法 5
也称页面淘汰算法。
- 缺页率 = 缺页中断次数 / 总访问次数
最佳置换(OPT : Optimal)
淘汰未来最长时间不妨问的、以后不会再用的页面 (预知未来)。
-
优:缺页率最小、性能最好。
-
缺:理想型算法,无法实现。
先进先出(FIFO)
淘汰最先进入内存的页面,维护一个有先后次序的队列。
-
优:实现简单
-
缺:性能最差,Belady 异常:可调动的物理块数越多,可能缺页中断次数也变多。
- 最早调入的页面,可能是使用最频繁的页面。
最近 / 最久未使用置换(LRU:Least Recently Used)
淘汰过去最久没访问的页面。维护页面的访问字段:上次访问时间t,淘汰t最大的页面。
-
优:性能尚可
-
缺:需要硬件支持,算法开销大,每次淘汰时,需要遍历统计访问次数的数据结构。
时钟置换(CLOCK)/ 最近未用(NRU:Not Recently Used)
(1)简单时钟置换(NRU)
给每个页面设置访问位:1 有访问,0无访问。表示该页最近是否有被访问。
维护一个指向内存中所有页面的循环链表。当程序访问链表中的页面时,就设置访问位为 1,当在链表中找不到时,就需要挑选一个为 0 的淘汰掉,然后插入需要访问的页面。
-
淘汰时:
-
第一轮:循环检查访问位,遇 0 则选择换出;遇 1 则置为 0 后,继续检查。
-
第二轮:如果原先全为 1,需要第二轮查找,此时已经全部置为 0,一定能找到可替换的页面。
-
-
优:实现简单,开销小,不需要很多硬件支持;
-
缺:未考虑如果页面被修改,需要输出到外存中,有外存写入开销。
(2)改进型时钟置换(改进型NRU)
优化:优先淘汰被修改过的页面。
-
统计:访问位 + 修改位。(1 , 1)表示(被访问过+ 被修改过)
-
淘汰时:
- 第一轮:淘汰(0 , 0),不修改数值,只为找到(0,0)的可替换位。
- 第二轮:淘汰(0 , 1),扫描过的页面,访问位 都置为 0。
- 第三轮:淘汰(0 , 0),不修改数值,只为找到(0,0)的可替换位,此时访问为都为 0,一定能找到可替换的页面。
-
优:考虑全面,算法开销适中,综合性能尚可。
第四章:文件管理
问题:文件基本知识
文件系统负责管理文件,为用户提供对文件进行存取、共享、保护的方法。
- 逻辑结构:用户角度观察到的文件组织形式。——逻辑地址
- 目录结构:文件之间的组织与管理。
- 物理结构:计算机实际的组织形式,在外存中的存放方式。 —— 物理地址
- 存储空间管理:外存中空间块的管理。
- 文件共享 / 保护:操作系统提供的其他支持。
- 系统调用:操作系统向上提供的基本功能。
- 基本操作 6:创建、删除、打开、关闭、读文件、写文件。
问题:文件的打开过程
- 系统将文件的属性从外存复制到内存,并设定一个编号(索引),返回给用户。
- 当用户要对该文件进行操作时,不需要查询目录,只需利用索引向系统提出请求。
避免了系统对文件的再次检索,节约了检索开销,提高了对文件的操作速度。
- 用户:看到文件的 逻辑结构。操作系统:通过 目录 找到文件的 FCB 信息,通过 FCB 信息,找到文件的 物理地址 / 索引地址,最终找到 物理地址,通过 物理结构 访问到具体的 物理地址,得到结果。
问题:文件的逻辑结构
文件的物理结构:从计算机角度出发,文件在外村上的存放和组织形式。
文件的逻辑结构:用户观察到的文件组织形式,是用户可以直接处理的数据和结构。
文件的逻辑结构划分为:
- 无结构文件:流式文件
- 有结构文件:记录式文件(类似表格):关键字(key)+ 数据项。
- 可变长记录:数据项长度不确定。
- 定长记录:数据项长度严格一样。
💊 顺序文件
连续结构。最简单的文件结构。将一个逻辑文件的信息连续存放。
- 存放位置:
- 逻辑上:顺序排列
- 物理上:相邻 (顺序存储) 、不相邻 (链式存储)
- 链式存储 无法实现随机存取,只能从头查找。
- 排序方式:
- 串结构:按存放时间记录,与关键字顺序无关。
- 顺序结构:按关键字顺序排放。支持关键字快速查找。
- 记录的长度:
- 变长记录顺序文件:无法随机存取,查询时只能从头依次查找。
- 定长记录顺序文件:可随机存取,支持查询随机访问。
顺序结构 + 定长记录 的顺序文件:可以实现关键字快速查找、随机访问。
通常来讲,默认顺序文件是:物理上 顺序存储 + 串结构 的文件。
- 缺点:不方便 增 / 删 文件。连续存放碎片较多,可变长不易快速检索。
- 优点:实现简单,可以支持随机存储。
💊 索引文件
索引结构为一个逻辑文件的信息建立的一个索引表。
- 索引表:一个定长记录的顺序文件,可快速查找索引项。
- 索引号(隐含) + 长度 + 指针地址
- 索引表不唯一,可根据数据项的不同建立多个类型的索引表(数据库)
- 逻辑文件:在物理上可以离散存放,通过索引项查找。
- 优点:解决了可变长记录文件的随机访问;方便 增 / 删 文件。
- 缺点:引入索引表,增加存储空间开销;查表需要设计算法。
💊 索引顺序文件
类似一本书。有目录(索引表),章节(分组)。
- 逻辑文件:按顺序把文件进行分组,得到关键字(章节)。
- 索引表:按照关键字排序,建立索引表。
- 索引项:是每个分组的第一项记录 (每章节的开头)。
- 查找方式:
- 顺序查找索引表。
- 找到分组。
- 顺序查找分组。
优点:缩短索引表长,提升存取速度;记录过多,可以建立多级索引。
问题:文件的目录结构
实现方式
- FCB 文件控制块:每个文件都对应一个 FCB,记录文件相关属性。
- 文件目录:由 n 个 FCB 项组合而成。目录项就是 FCB。
- 操作方式:搜索、创建、删除、显示、修改文件。
索引节点:对 FCB 进行改进。
- 改进原因:找文件需要查看文件名,而 FCB 的目录项过大,全部从外存中调入开销增大。若目录项过大,占用多个磁盘块,在查找时,一次只能读一个磁盘块,需要多次 I/O。
- 目录项:不再保存完整的 FCB,而只保存 [文件名, 索引结点指针]。每个文件建立一个索引结点,通过指针找到结点。这样就缩小了目录的体积。
💊 目录的结构 4:
单级目录结构 (原始)
整个系统只有一张目录表,每个文件为一个表项。
- 缺:查找速度慢,文件不允许重名。
两级目录结构 (用户分类)
系统为每个用户建立一个单独的用户文件目录 UFD User File Directory。
- 文件目录结构:1 个主文件目录 MFD + n 个用户文件目录 UFD。
主文件目录:记录系统中各个用户文件目录。
用户文件目录:记录该用户建立的所有文件和说明信息。
-
优:查找速度提高,不同用户文件可以重名,增加用户间权限。
-
缺:不方便于用户间的文件共享,无法对文件分类。
多级目录结构 / 树形结构 �(路径寻找)
将二级目录结构推广,变成多级目录结构。通过路径名来唯一标识文件。从根路径出发为绝对路径,从当前目录出发为相对路径。
-
结构:1 个根目录 + n 个子目录。 每个文件有唯一标识符,对用户透明。
-
优:可对文件分类、可重名、结构清晰。
-
缺:不方便文件共享、目录较多会频繁 I/O 操作,影响查找速度。
无环图目录结构(用户共享)
在树形结构的基础上,增加指针。可以让不同文件名,指向同一文件。
-
这种方法在删除文件时增加麻烦。类似 js 的对象销毁机制。需要对引用计数,记录用户链接到该文件的总数。当引用数量为 0 时,才可以销毁。
-
优:可以共享文件。
-
缺:结构更复杂,不方便管理。
问题:硬链接 / 软链接
文件共享是一个重要功能。是指不同的用户可以使用同一个文件。实现方式有 硬 / 软链接 两种方式。
基于索引结点的共享方式(硬链接)
类似 js 中不同的指针指向相同的 object 对象。
索引结点,是把 FCB 中的文件描述信息单独构成一个数据结构,也就是说,物理块的信息在索引结点中保存。所以目录中可以只保存 文件名 + 索引指针,大大减少了目录体积。
所以,硬链接的思想是让两个不同的目录项,指向相同的索引结点。也就是不同的目录名,保存的结点指针,指向了相同的的文件地址。这样就实现了共享。
- 优点:通��过索引指针,可以直接访问到对应的文件,速度快。
- 缺点:文件拥有者无法删除被共享的文件,因为其他用户保持了该文件的索引指针
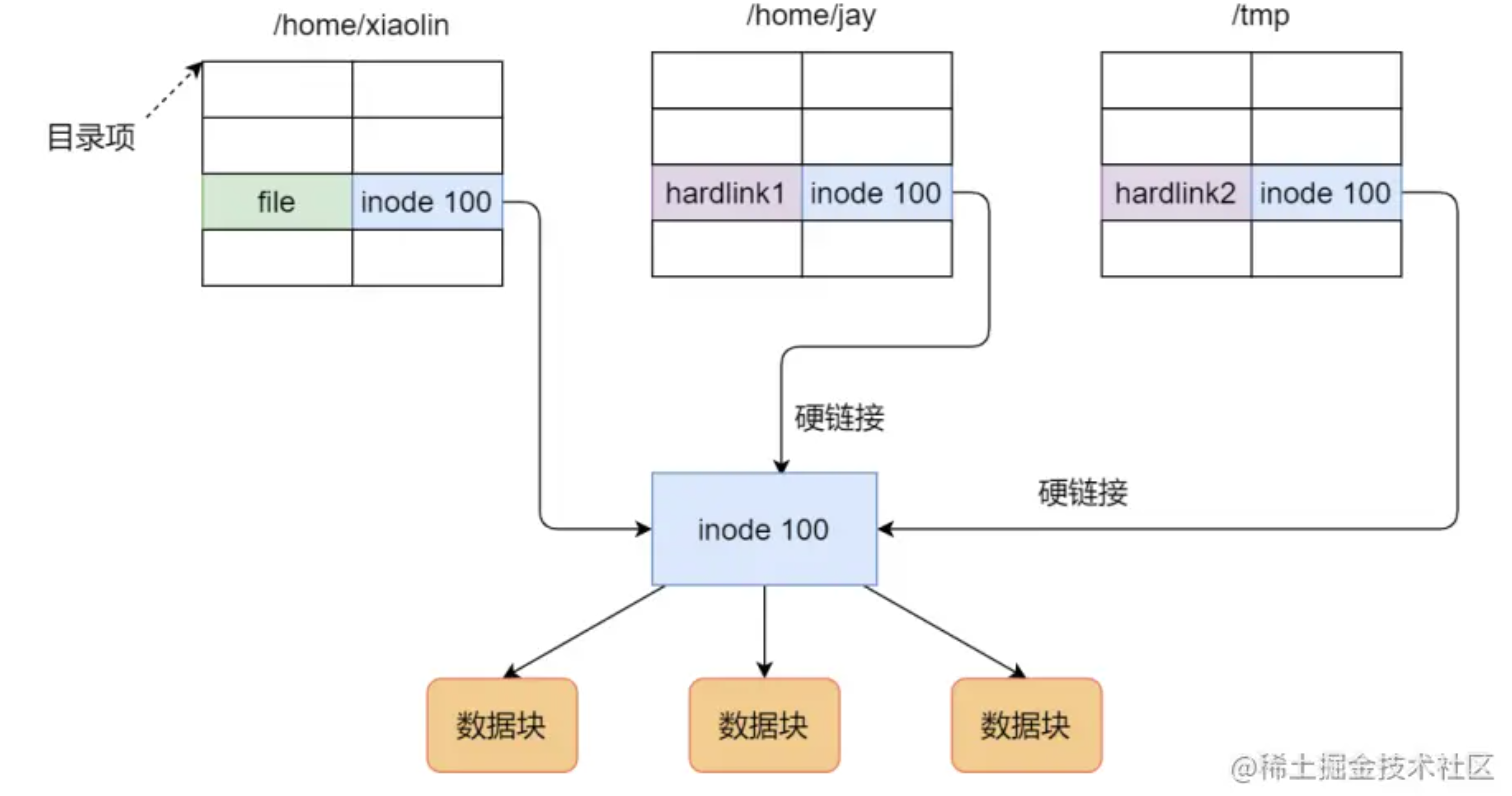
基于符号链实现文件共享(软链接)
类似 window 中的快捷方式。
目录可以新增一个 链接 类型的目录项。该目录项保存:文件名 + 文件路径。并不是保存索引指针,而是通过 文件路径,可以访问到其他文件,以实现共享效果。
-
如果 B 用户想访问 A 用户的某个文件。B 可以在自己的目录中创建一个新的目录项,该目录像并不是一个 文件 类型的目录,而是 链接 类型,同时保存了文件的路径。可以通过路径访问到 A 的那个文件。
-
优点:文件拥有者可以随意删除自己的文件。删除后,其他 链接 并不会被删除,只是不能正确访问文件。
-
缺点:通过 链接 访问文件,需要通过路径依次查找目录,开销很大。
问题:文件的物理结构
非空闲磁盘块的分配、外存的分配方式:
- 静态分配:文件建立时,一次性分配所需的全部空间;
- 动态分配:根据动态增长的文件长度进行分配,可以一次分配一个物理块。
顺序分配 / 连续分配
分配是连续的磁盘��块。用户必须提前说明文件大小,系统查找空闲区的管理表格,如果有连续的空间可以容纳,就分配空间;如果空间不足,用户进程必须等待。
- 目录项内容:起始块号,文件长度
- 优点:顺序存取速度快,支持随机访问。
- 缺点:产生碎片,空间不足需要紧缩技术。文件拓展不便。
链接分配 (离散分配)
用户事先不知道文件的体积,从用离散分配方式,分为:隐式链接、显式链接。
(1)隐式链接
每个磁盘块中,有一个指针指向下一个磁盘块,串联起来形成链表。
- 目录项内容:文件名,…,起始块号,结束块号
- 优点:解决外部碎片问题,外存利用率高,易于实现文件拓展。
- 缺点:由于是链表链接,只能从头顺序访问,不能随机读取,记录指针占用内存。
(2)显式链接
建立文件分配表,通过表可以直接查找所有的链接,而不需要在磁盘中顺次查找。一个磁盘对应一个FAT,且该表 常驻内存 中。
- 文件分配表 (FAT) 内容:物理块号 + 下一块号。
- 优点:隐式链接优点 + FAT 实现随机访问、不需要磁盘读取,加快速度。
- 缺点:FAT 占用一定的外存、内存空间。
索引分配
一个文件分配一个索引块,索引块中存放索引表,索引表中的每个表项对应具体的物理块。索引块在外存 / 磁盘中。
- 索引表表项内容:物理块(相当于页表)
- 目录项内容:文件名,…,索引块
- 优点:支持随机、顺序访问,文件易扩展,只需增加索引表表项即可。
- 缺点:索引表占用磁盘空间。访问数据块需要先读入索引块 (可常驻内存),增加额外的 I/O 操作。
改进:若索引表过长,可能需要占用多个索引块。
- 以空间换时间
-
链接方案
- 方法:把每个索引表用指针链接起来。
- 问题:索引需顺序查表,多次 I/O 频繁。
-
多层索引 (相当于多层页表)
- 方法:顶层索引块指向第二层索引块,以此类推。FCB 中只存放顶层索引块
- 问题:各表需要小于一个索引块 / 磁盘块 / 数据块。
-
混合索引 (根据需求调整索引层级)
- 目录项内容:可以是 索引块 / 数据块起始块号;
- 直接地址索引:直接指向数据块(两次I/O:索引块 + 访问数据)
- 一级间接索引:指向单层索引表(三次I/O:两次索引 + 访问数据)
- 两级间接索引:指向两层索引表(四次I/O:三次索引 + 访问数据)
问题:文件的存储空间管理
系统记录了空闲存储空间的情况,以便对存储空间进行分配。
磁盘划分为:目录区 + 文件区
- 目录区:存放 FCB、相关管理信息(空闲表、位示图、超级快等)
文件空闲存储空间管理 4 种办法:P217
空闲表法 (连续)
所有空闲文件单独建立一个目录。
- 空闲表:记录每个连续空闲区:(起始盘号,盘块数)
- 分配:首次适应、最佳适应、最差适应、邻近适应
- 连续分配 —— 动态分区分配
- 回收:分区合并 + 新增表项按算法排序
- 特点:实现简单,必须采用连续,有碎片。
空闲链表法 (离散 / 连续)
- 空闲盘块链:把每一个空闲磁盘块链接起来。
- 空闲盘区链:连续的空闲盘块组成一个空闲盘区。把空闲盘区链接起来,标明区内,块的数量
- 空闲盘块:离散方式;空闲盘区:离散 + 连续方式
- 回收 / 分配:与上相同。
- 特点:可离散,提高利用率;需要算法提高分配速度(链表需要从头顺次查找)
位示图法
把磁盘切分为 n 个物理块。统计物理块是否空闲。
- 位示图:0空闲盘;1已分配。一个磁盘块对应一个数字。
- 分配:四个适应算法;回收:把1置为0。
- 特点:位示图较小,可常驻内存中,提高分配速度;需要图中坐标与盘块号转换,增加开销
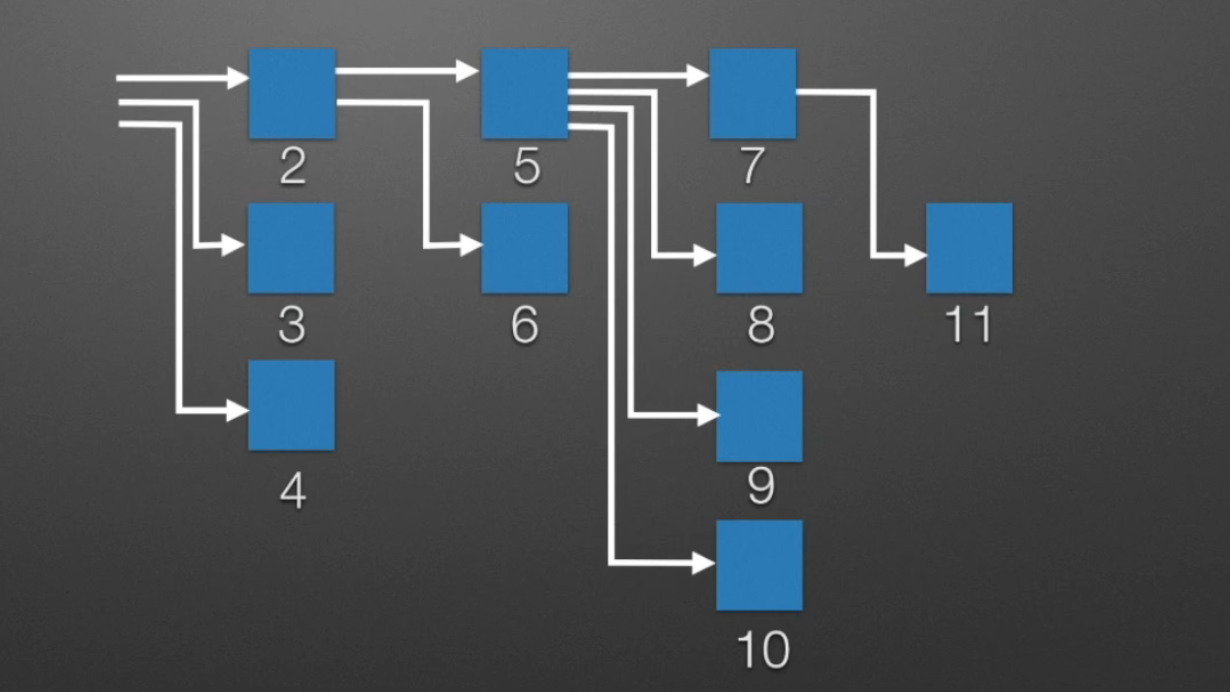
成组链接法(UNIX系统)
适用于大型文件系统。将一个文件的所有空闲快按每组 100 块分成 n 组。每组的第一个盘块中,记录了下一组所有盘块的地址。第一个组的盘块,被单独的超级块记录。
- 设置超级块 + 若干组(每组100个空闲磁盘)
- 每组第一个空闲块,记录下一组的相关信息(数量,块号)
- 第一组的信息,在超级块中记录。超级块常驻内存。
- 分配:检查超级块,充足则分配,不充足则分配第一组,同时修改链接信息。
- 回收:检查超级块,不超过100块则添加进超级块;超过则新建分组。
问题:文件的保护
口令保护
每个文件设置一个 “口令”,保存在 FCB 中,用户必须对口令访问。
- 优:开销小(口令占用少量空间);验证时间段( PCB 中口令对上即可)
- 缺:口令在系统内不安全,攻破后随意访问。
加密保护
使用 “密钥” 对文件加密,对称密钥,非对称密钥。
- 优:安全性强,改变了数据内容,密码不放在系统中。
- 缺:加密 / 解密开销大。
访问控制
在 FCB 中,建立访问控制表(ACL),记录各用户对文件的访问权限。
- 优:灵活,权限相同,则用户可按组记录。
- 缺:表有开销,一个目录有权限信息,其内容也要加权限信息
问题:文件系统层次结构
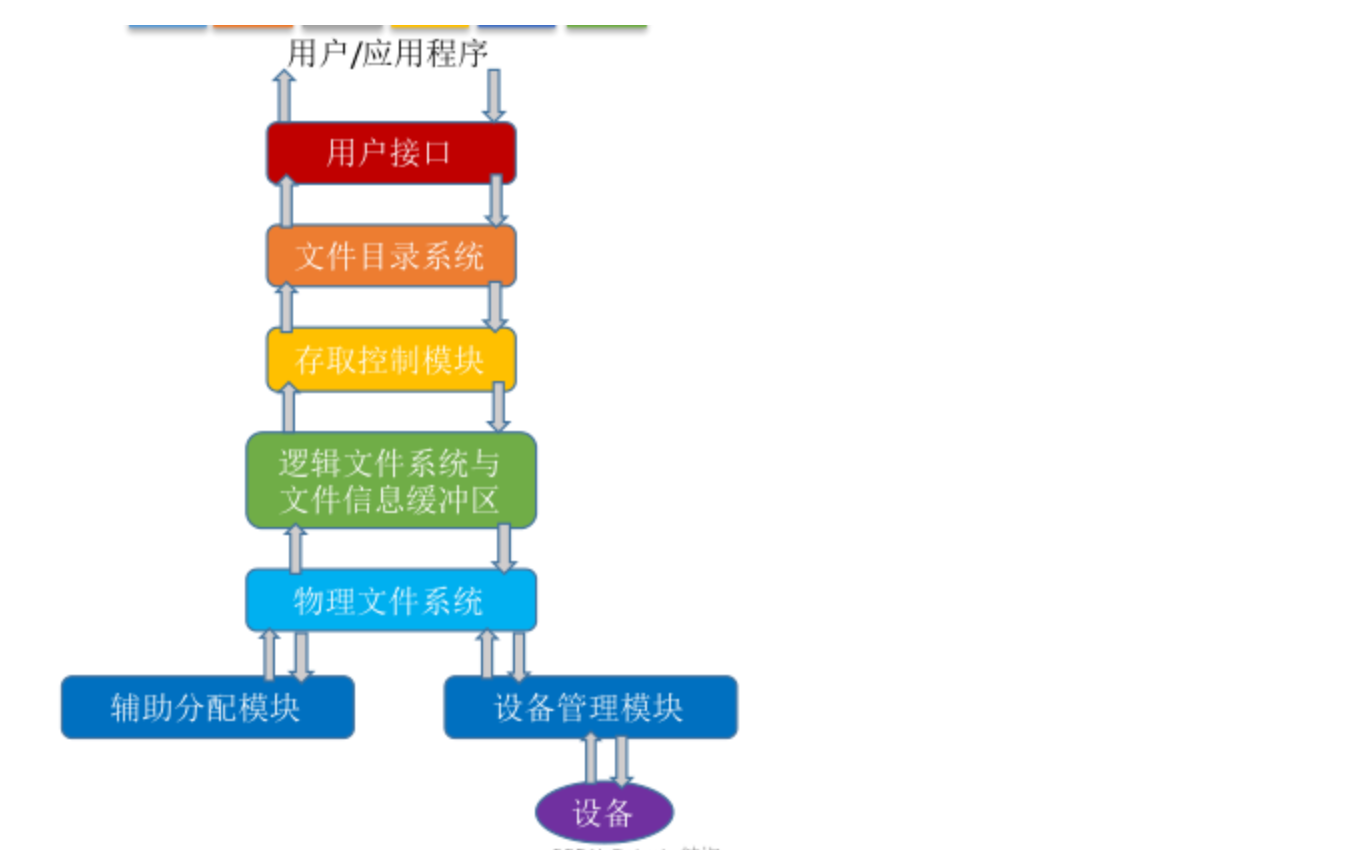
用户 => 用户接口 => 文件目录系统 => 存取控制模块 => 逻辑文件系统与文件信息缓冲区 => 物理文件系统
- 物理文件系统:辅助分配模块 + 设备管理模块 ( => 设备)
问题:磁盘调度算法
磁盘、磁道、扇区
-
磁道:磁盘划分的一圈一圈的范围。通过磁头移动,改变柱面,更换磁道。
-
扇区:= 磁盘块。每一圈又划分为小段小段。
-
磁盘的物理地址 = 柱面号,盘面号,扇区号。
磁盘调度算法 2 + 4
磁盘是可以被多个进程共享的设备。当有多个进程都请求访问磁盘时,采用适当的算法,保证各个进程对磁盘的平均访问时间(主要是寻道时间)最短。
1. 先来先服务(FCFS)
按照先后顺序依次寻找、访问。
- 优:公平,如果访问的磁道集中,则性能尚可。
- 缺:若进程竞争使用,磁道分散,寻道时间很长,性能极差。
2. 最短寻找时间优先(SSTF)
优先处理与当前磁头最近的磁道。
- 优:平均寻道时间短。
- 缺:确保短期寻道时间最短,不一定总体寻道时间最短。有些进程会饥饿。
3. 扫描算法(SCAN)
改进:解决最短寻找时间优先的饥饿问题,让磁头在触碰磁道边缘才能往返移动。
- 磁头必须移动到最外侧磁道,才能往回移动。移动期间访问队列中的磁道。
- 优:性能较好,解决饥饿问题,
- 缺:
- 达到边缘才能返回。 改进:LOOK 算法
- 边缘的磁道响应间隔不平均。 改进:C-SCAN 算法
4. LOOK 调度算法 —— 电梯算法
改进:如果磁道在当前方向上没有访问请求,则可以提前掉头。
- 优:寻道时间比扫描算法进一步缩短。
5. 循环扫描算法(C-SCAN)
改进:磁头必须沿一个方向扫描。扫描到最边缘时,掉头直接回到初始端,重新扫描。
- 优:对各个位置的磁道响应频率很平均。
- 缺:只有达到最边上才掉头,浪费了时间。 改进:C-LOOK 算法。
6. C-LOOK 调度算法
改进:方向上没有访问请求,则立刻掉头。同时,掉头不是回到初始端,而是请求位置。
- 优:结合了 LOOK 和 C-SCAN 算法,寻道时间最短。
问题:提高磁头读取速度的办法
- 交替编号
- 办法:编号相邻的扇区,物理上不相邻。
- 原理:读完一个扇区,需要间隔时间后再读。
- 错位命名
- 办法:同一个柱面下,扇区号错位。不同盘面(垂直看),扇区号要垂直错位。
- 原理:读完某盘面的最后一个扇区后,下一个扇区在另一个盘面上,要错开扇区编号。
- 磁盘地址结构设计
- 地址:柱面号,盘面号,扇区号
- 柱面最后移动,因为移动柱面要移动磁头,费时间。
第五章:设备管理
问题:设备控制器的功能 4
- 接受和识别来自 CPU 的命令
- 实现 CPU 与设备控制器、设备控制器与设备之间的数据交换
- 记录设备的状态供 CPU 查询
- 识别所控制的每个设备的地址
- 对 CPU 输出的数据或设备向 CPU 输入的数据进行缓冲
- 对 I/O 数据进行差错控制
问题:I/O 控制方式 4
控制方式
- 特点:CPU干预频率↘️,一次 I/O 的传输量↗️,数据流向经过的设备↘️。
- 改进:每个方式的优点,就是改良上个阶段的缺点;减少 CPU 对 I/O 干预。
程序直接控制方式
早期的计算机系统中,没有中断系统。CPU 和 I/O 设备通信时,
过程:
1. CPU 对 I/O 控制器发出命令后,便不断轮询。
1. 等待 I/O 控制器完成,才进行下一条指令。
1. CPU 发出从 (内存/外设) 读命令、发出向 (内存/外设) 写命令。
数据流向:I/O设备 ↔️ CPU ↔️ 内存
- 优:实现简单。
- 缺:
- 早期 OS 无中断系统,I/O 设备太慢,CPU 盲等,利用率低。
- 传输单位是字节,效率低。
中断控制方式
广泛采用的方式,为了减少 CPU 等待时间,提高 CPU 与 其他设备的并行工作时间
过程:
- CPU 发出命令后,阻塞需要 I/O 的当前进程,切换至别的进程执行。
- 等 I/O 操作完成后,I/O 控制器发出中断信号。CPU 检测到中断,继续执行进程。
- CPU 发出从 (内存/外设) 读命令、发出向 (内存/外设) 写命令。
要点:CPU 中断检测时机:每个指令周期的末尾。
数据流向:I/O设备 ↔️ CPU ↔️ 内存
- 优:提高利用率。实现了 I/O 设备与 CPU 并行工作。
- 缺:
- 执行中断指令需要保护现场,切换进程,频繁中断,增加开销。
- I/O 设备与内存间数据传输,总是需要 CPU 参与,浪费 CPU 利用率。
- 传输单位是字节,效率低。
**DMA 控制方式 ** (直接存储器存取 — DMA 存储器)
以内存为中心,在外设和内存之间开辟一个直接交换数据的通路。
过程:
-
CPU 执行的进程,现在需要 I/O 操作。
-
CPU 发出命令,直接一次性说明所有信息 (数据量、读地址、写地址),交给 DMA;
-
DMA 控制器在完成一系列指令后,发出中断信号。CPU 检测到中断,切换回来;
-
此时已完成读 / 写命令,直接进入下一个指令周期。
数据流向:I/O设备 ↔️ 内存
-
优:
-
传输单位是 “数据块”,连续读写,提高传输速度。
-
数据传输不需要 CPU 干预,DMA 控制器完成。
-
-
缺:
- 数据的传送方向、存放输入数据的内存起始地址等都有 CPU 控制。所以 CPU 一条 I/O 指令,只能 读/写 连续的数据块,无法 读/写 离散的。
- 每台外设设备,都需要一个 DMA 控制器。当有多台设备时,不经济。
DMA 控制 与 中断控制 的区别:
- 中断控制方式,在每个数据传输完成后,中断 CPU; DMA 控制方式,在所要求的全部数据传输完成后,中断 CPU。
- 中�断控制方式,中断处理由 CPU 控制; DMA 控制方式,DMA 控制器完成。
通道控制方式(弱鸡版 CPU)
以内存为中心,实现设备与内存直接交换数据的控制方式。
过程:
- CPU发出 I/O 命令,一致性说明所有信息,交给通道。
- 一个通道可以控制多个设备,会自行执行全部 I/O 指令,完成后发出中断信号。
- CPU 切换回来执行下一个指令周期。
要点:通道是一个简化版 CPU。专门完成 I/O 任务,与 CPU 共享内存。
数据流向:I/O设备 ↔️ 内存
- 优:
- CPU、通道、I/O 设备 均可以并行工作,利用率最高。
- 一条指令,可传输一组数据块,数据可离散。
- 缺:通道实现需要硬件支持,更复杂。
问题:I/O 软件的层次结构
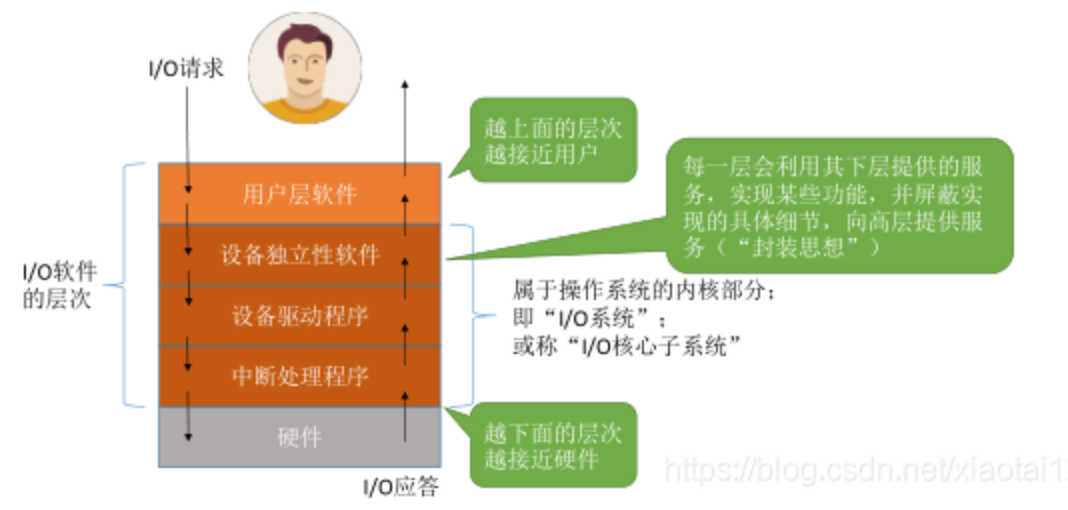
-
用户层软件
-
提供:操作系统与用户交互接口。把用户请求翻译为格式化I/O请求。SPOOLing
-
服务:I/O操作相关的库函数。
-
-
设备独立性软件
-
提供:
-
向用户提供同一的调用接口。
-
设备:保护/分配/回收 (读取权限 / I/O磁盘调度)。映射对应驱动程序。
-
数据:差错处理、缓冲区管理。
-
转换:逻辑 / 物理设备名称映射
-
-
服务:系��统调用功能。
-
要点:与硬件无关的、对设备和数据管理的操作。
-
-
设备驱动程序
-
提供:
-
每一类设备配置一个驱动程序。
-
逻辑设备表(LUT),物理设备与驱动程序地址的映射。
-
将上次指令转化为特定硬件的具体 (听得懂) 的指令。
-
-
要点:与硬件相关的,涉及到具体硬件的操作。
-
中断处理程序
- 提供:
- 控制 I/O 设备、内存、CPU 之间数据传输的方式。
- 当 I/O 操作完成,发出中断信号,CPU 收到反馈,执行下一周期的指令。
- 提供:
问题:假脱机技术(SPOOLing)
假脱机技术:SPOOLing 技术。独占设备在系统中数量有限。有些进程可能长期持有独占设备但可能不经常使用设备,而导致设备利用率低。通过共享设备来虚拟独占设备,提高了设备利用率。
脱机技术
-
脱机:脱离主机控制,进行输入/输出操作。
-
外围控制机 + 高速设备(磁盘):读取速度比纸带机快。
早期系统中,缓解设备与 CPU 处理速度的矛盾。实现 CPU 与设备并行。纸带打印的速度非常慢,严重拖累了 CPU 的运行效率,所以引入了外围控制机和磁带。CPU 只对磁带进行 I/O 操作,提升了速度。外围控制机负责把磁带的数据写入到纸带上。这样 CPU 得到解脱。
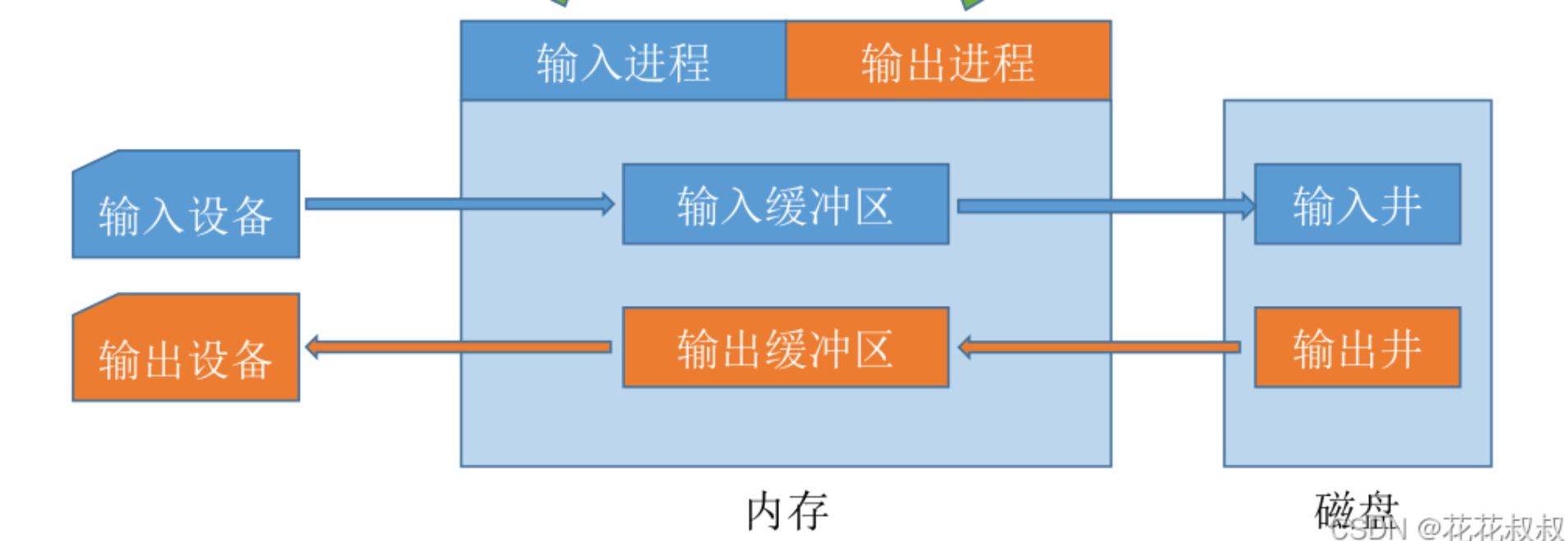
假脱机技术
输入 / 输出井:
- 是在磁盘上开辟的两个存储区。
- 模拟脱机输入 / 输出的磁带,用于收容 I/O 设备输入 / 用户进程输出的数据;
输入 / 输出缓冲区:
- 是在内存中开辟出来的两个缓冲区。
- 缓冲区装满后,才执行输入输出。
输入 / 输出进程:
-
模拟脱机输入 / 输出时的外围控制机。
-
在输入进程的控制下,输入缓冲区 暂存从 输入设备 输入的数据,之后再转存到 输入井 中;
-
在输出进程的控制下,输出缓冲区 暂存从 输出井 输入的数据,之后再传送到 输出设备 上。
过程:磁盘(输入井/输出井) ↔️ 内存(输入/出 缓冲区) ↔️ 设备(输入/出目的地)
优点:
- 速度匹配技术。提高 I/O 速度(CPU => 内存 => 外存 => 设备)。
- 虚拟设备技术。设备没有分配给进程。进程得到的是一个存储区 + I/O 申请表。
- 提高利用率。实现了设备虚拟共享的功能,提高设备利用率。
应用:共享打印机
- 打印机是独占类设备,多个进程不可同时操作。
- 通过 SPOOLing 技术,把打印机虚拟化,可以让进程交替使用打印机,形成打印队列。
问题:缓冲区的分类与结构
缓冲区作用:
- 提高 CPU 与 I/O 设备的并行程度。
- 缓和 CPU 与 I/O 设备速度不匹配的矛盾。CPU 总是等待 I/O 设备。
- 减少 CPU 的中断频率。
- 解决数据粒度不匹配。eg 一次I/O,进程一块数据,磁盘一个字符
单缓冲:
最简单的缓冲形式。当用户进程发出一个 I/O 请求,操作系统在内存中为它分配一个缓存区。CPU 和设备的 I/O 读写都通过缓冲区,设备、CPU对缓冲区是串行的。
- 流程: CPU(处理) ⬅️ 进程工作区(内存) ⬅️ 缓冲区(内存) ⬅️ 设备
- 要点:工作区的数据一慢,CPU 可立即处理完。
- 处理一块数据平均耗时:
- max ( CPU处理时间 , 缓冲区冲入时间 ) + 工作区冲入时间
双缓冲:
-
改进:在单缓冲基础上,增加一个缓冲区,可交替冲入 / 冲出数据。
-
处理一块数据平均耗时:
- max ( CPU处理时间 + 工作区冲入时间 , 缓冲区冲入时间 )
两设备通信时,单双缓冲的区别:
- 单缓冲:半双工通信 (单向传输);
- 双缓冲:全双工通信 (双向传输)
循环缓冲
- n 个大小相等的缓冲区,链接成一个循环队列。
- 设置 in 指针,指向下一个空缓冲区;设置 out 指针,指向下一个满缓冲区。
- 当用户进程需要数据时,从循环缓冲中取出一个装满数据的缓冲区,提取数据。
- 当 I/O 设备写入数据时,向循环缓冲中的空区写入数据。
缓冲池
- n 个缓冲区
- 组成三个队列:空缓冲队列、装满后要输出对队列、装满后要输入对队列
- 组成 4 种工作缓冲�区
- 收容输入数据的工作缓冲区(hin);
- 提取输入数据的工作缓冲区(sin)
- 收容输出数据的工作缓冲区(sout);
- 提取输出数据的工作缓冲区(hout)